
The effective context window is the usable portion of an LLM's advertised token limit where the model maintains coherent reasoning — typically just 50-60% of what vendors advertise. After spending hundreds of hours building AI agents and coding with tools like Cursor, the pattern is undeniable: your model doesn't just get slower as context grows — it gets significantly dumber. Relying on infinite context isn't just inefficient — it's a dangerous architecture decision.
The degradation zone
Let's break it down. When you push an LLM to its limit, you're not getting linear performance. You're entering a degradation zone. Take Gemini, for example. They might declare a 128K token window, but in practice, the effective window - where the model actually stays coherent - is closer to 64K. That's half the size.

I see this constantly when using coding agents like Cursor — a pattern that affects AI-assisted software development teams wherever session-length context grows unchecked. I can clearly notice the moment the model breaks. At the start of a session, it's sharp. But as the context grows, it starts hallucinating, forgetting previous instructions, or rewriting code it just fixed. It's a phenomenon known as U-shaped attention. Transformers are great at remembering the beginning and the end of a prompt, but they have a terrible habit of losing information in the middle.
This isn't just a minor annoyance. It's a fundamental flaw in how we think about AI memory. We've been sold a narrative that 'bigger is better.' But high-signal coherence beats massive context every single time. If you're dumping your entire knowledge base into a prompt window expecting magic, you're actually orchestrating a failure. The model becomes overwhelmed by noise, and the specific, critical details you need it to act on get buried in the middle where its attention is weakest.
Engineering for reality
So, what's the fix? You have to stop chasing the infinite context dream and start thinking like an engineer. The game has changed from 'how much data can I fit?' to 'how do I orchestrate high-quality data flow?'
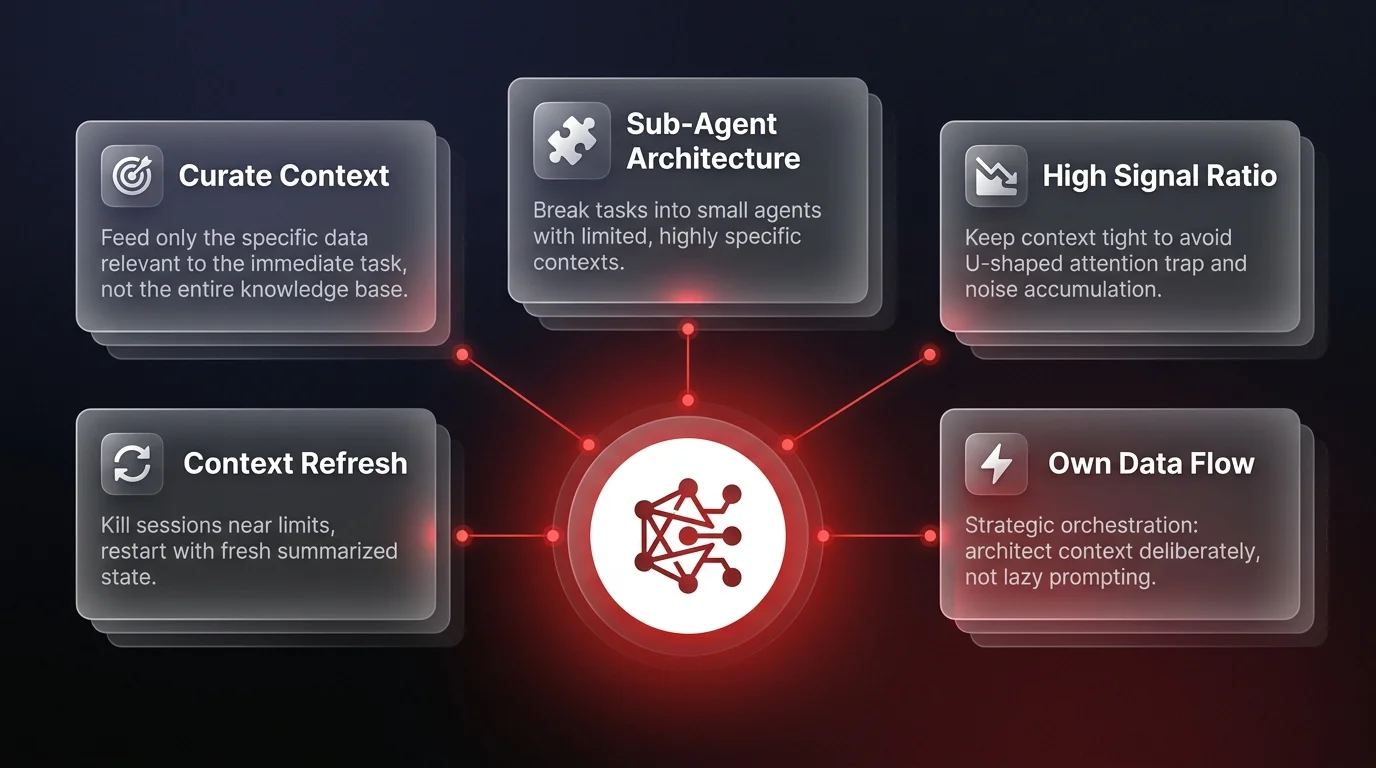
The answer lies in radical modularity. Forget about the infinite context. Embrace modular architecture. Instead of one giant agent trying to hold the entire state of your project, you need to break tasks down. Use sub-agents with limited, highly specific contexts.
This approach amplifies accuracy because you're feeding the model only what it absolutely needs to solve the immediate problem. It's about context engineering. You need to curate the input. If you're building a customer support agent, don't feed it the last five years of ticket history. Feed it the specific policy relevant to the current intent.
By keeping the context tight, you avoid the U-shaped attention trap. You keep the signal-to-noise ratio high. This is how you build robust systems that don't degrade over time. It requires a shift in mindset - from lazy prompting to strategic architecture. You have to own the data flow, not just the prompt.
Building reliable systems
Building reliable AI agents isn't about buying the model with the biggest specs. It's about how you assemble the pieces. At Ability.ai, we specialize in orchestrating agent architectures that prioritize coherence over raw size. If you're ready to stop fighting model degradation and start shipping systems that actually work, let's talk.