
Context rot is the performance degradation that occurs when AI agents operate near their context window limits — where models don't just slow down, they get significantly dumber. Despite vendor claims of million-token windows, practical experience building agentic workflows shows that LLM reasoning quality degrades sharply past 100K tokens. If you are building automated systems based on vendor specs rather than operational reality, you are building a house of cards.
Performance degradation
Let's break down what actually happens when you push these models to their limits. I was recently working on a complex coding task with Claude. The session counter ticked past 86k tokens. To an outsider believing the hype, this sounds fine - after all, isn't the limit supposed to be 200k or even a million? But I knew I was walking into a minefield.
The reality is that performance degrades non-linearly. Up to about 100k tokens, you generally get high-signal responses. The model follows instructions, maintains logic, and remembers constraints. But cross that invisible line, and the rot sets in. I've seen it repeatedly: at 150k tokens, I don't just suspect errors; I guarantee them. The model starts hallucinating APIs that don't exist. It forgets the primary directive I gave it at the start of the session. It starts 'doing dumb stuff' that makes you question why you're using AI in the first place.
This isn't just about memory; it's about reasoning capacity. The 'attention' mechanism in these transformers gets diluted. It's like trying to listen to a whisper in a crowded stadium. The more data you force into the context, the more noise you introduce. Vendors might technically support a million tokens - meaning the code won't crash - but the effective intelligence at that scale is practically zero for complex, multi-step agentic tasks. You have to stop trusting the brochure and start trusting the behavior you see in the logs.

Managing context lifecycle
So, how do we solve this? We have to flip the script on how we architect AI agents. Instead of treating context as an infinite bucket, we must treat it as a scarce, degrading resource. You have to take ownership of the lifecycle of your agents.
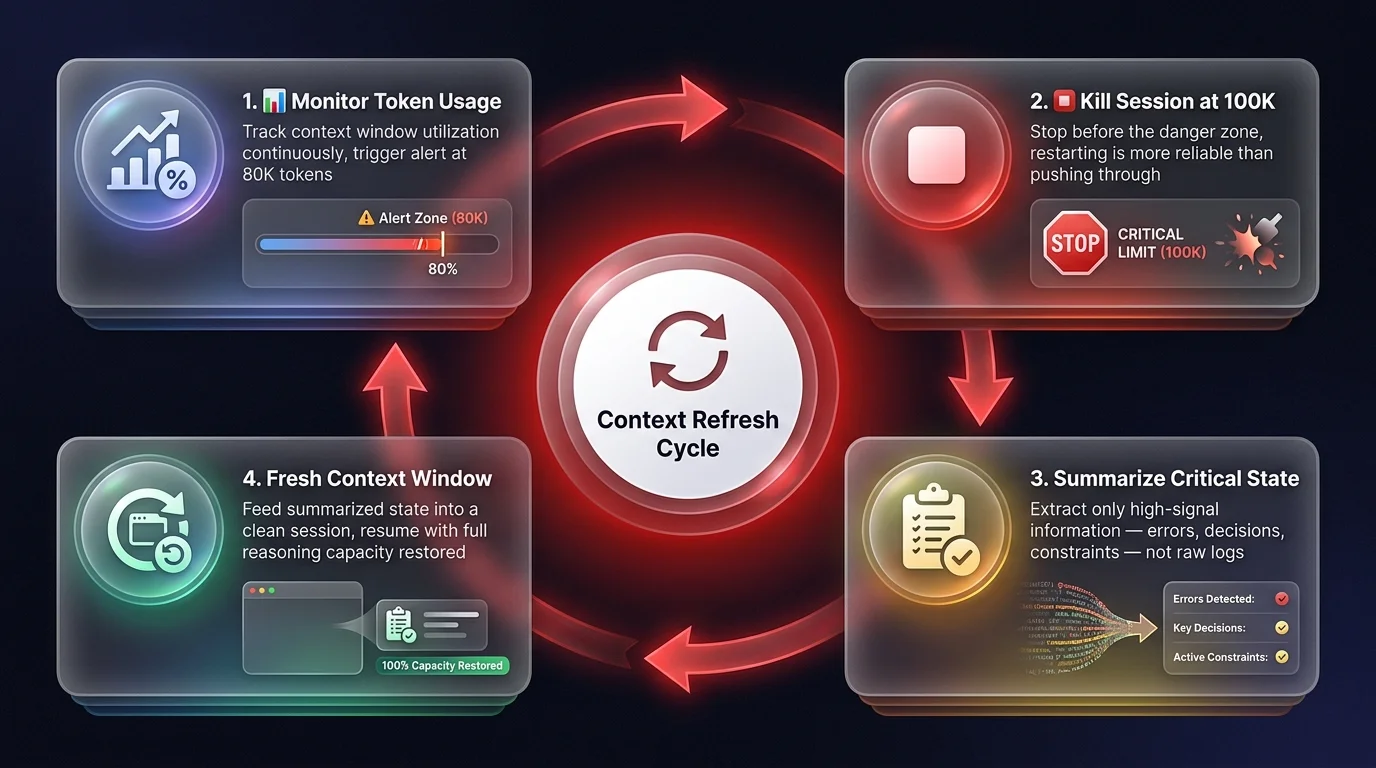
The most effective strategy is strictly limiting task scope. When an agent approaches that 100k danger zone, you don't push through - you kill the session. It sounds radical, but restarting is the only way to ensure reliability. You need to build agentic orchestration layers that monitor token usage and automatically trigger a 'context refresh'.
This involves summarizing the current state - extracting only the critical, high-signal information - and feeding that into a fresh, clean context window. It's like letting your employee take a nap and giving them a fresh briefing, rather than forcing them to work 48 hours straight.
You must also be ruthless about what enters the context in the first place. Don't dump raw logs; dump summarized error reports. Don't upload the whole repo; upload the relevant interfaces. By managing context density and respecting the 100k limit, you amplify the model's intelligence rather than drowning it. This kind of context-aware operations automation is what separates reliable production agents from demos that break at scale. The game has changed - success isn't about how much context you have, but how effectively you curate it.
Building production systems
Don't let context rot silently kill your project's success rates. At Ability.ai, we design autonomous agents that respect the physics of LLMs, ensuring consistent, high-value output without the hallucinations. Ready to build systems that actually work in production? Let's talk.