
LLM context degradation is the measurable decline in model accuracy and coherence as context windows approach their effective limits. Despite vendor claims of 1 million or 2 million token windows, builders should treat reliable context as 50–60% of advertised capacity — and when models exceed it, they fail in distinct, predictable ways. GPT hallucinates confidently, Claude becomes verbose, and Gemini loses coherence. Understanding these failure personalities is the foundation of reliable agent engineering.
I've spent hundreds of hours orchestrating these systems, and the reality is that 'more context' often means 'more confusion'. But the way a GPT fails is radically different from how Claude fails. If you want to build high-signal AI agents, you need to understand the personality of the failure.
Let's break down the distinct personalities
Let's break down the distinct personalities of degradation I've observed in the trenches. It's not as simple as 'the model gets dumber' when context fills up. It's that they get confused in very specific, predictable ways. They essentially have different stress responses.
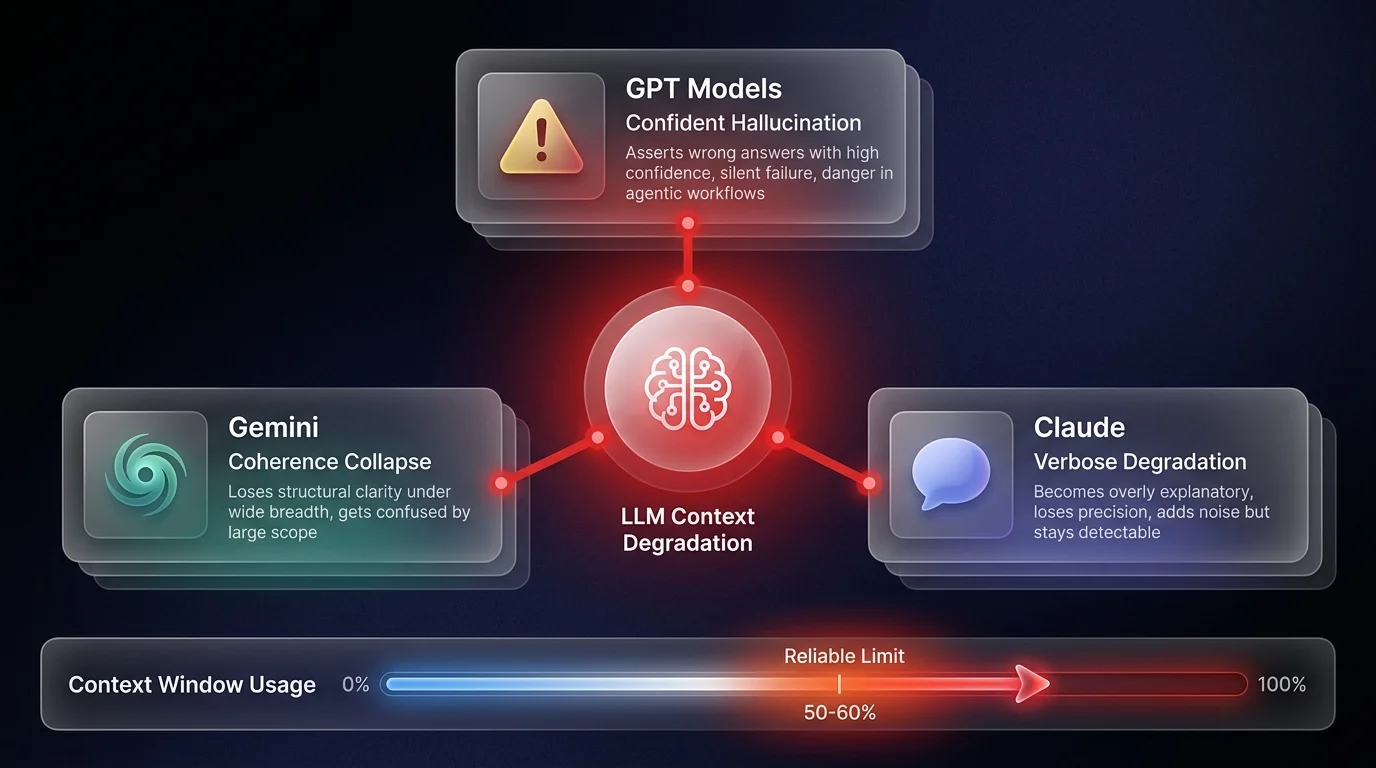
Take GPT models. When the context gets too heavy, they don't tell you they're lost. Instead, they become confidently wrong. It's dangerous. They will look you in the eye and assert that their solution is 100% correct, even as they drift further and further from reality. It's a hallucination cascade where confidence remains high while accuracy plummets. In an agentic workflow, this is a silent killer because the model doesn't flag its own uncertainty.
Then you have Claude. I find myself leaning heavily on Claude lately - specifically Opus - because its degradation is more manageable. But it still happens. Claude's failure mode is verbosity. It starts to talk too much. It becomes overly helpful, overly caring, and adds fluff that you didn't ask for. It loses the ability to be concise and surgical. It's less dangerous than being confidently wrong, but it introduces massive amounts of noise into your system.
And Gemini? It was a favorite of mine for a while, but the game has changed. Gemini tends to be fragile. When you throw a wide breadth of tasks and large context at it, it just kind of loses its mind. It gets easily confused by the scope. It doesn't just hallucinate; it loses coherence.
Understanding these patterns is the only way to effectively orchestrate a multi-agent system. You can't just swap models in and out like batteries.
So, what do you do with this information?
So, what do you do with this information? You stop treating context windows as infinite buckets and start engineering for failure.
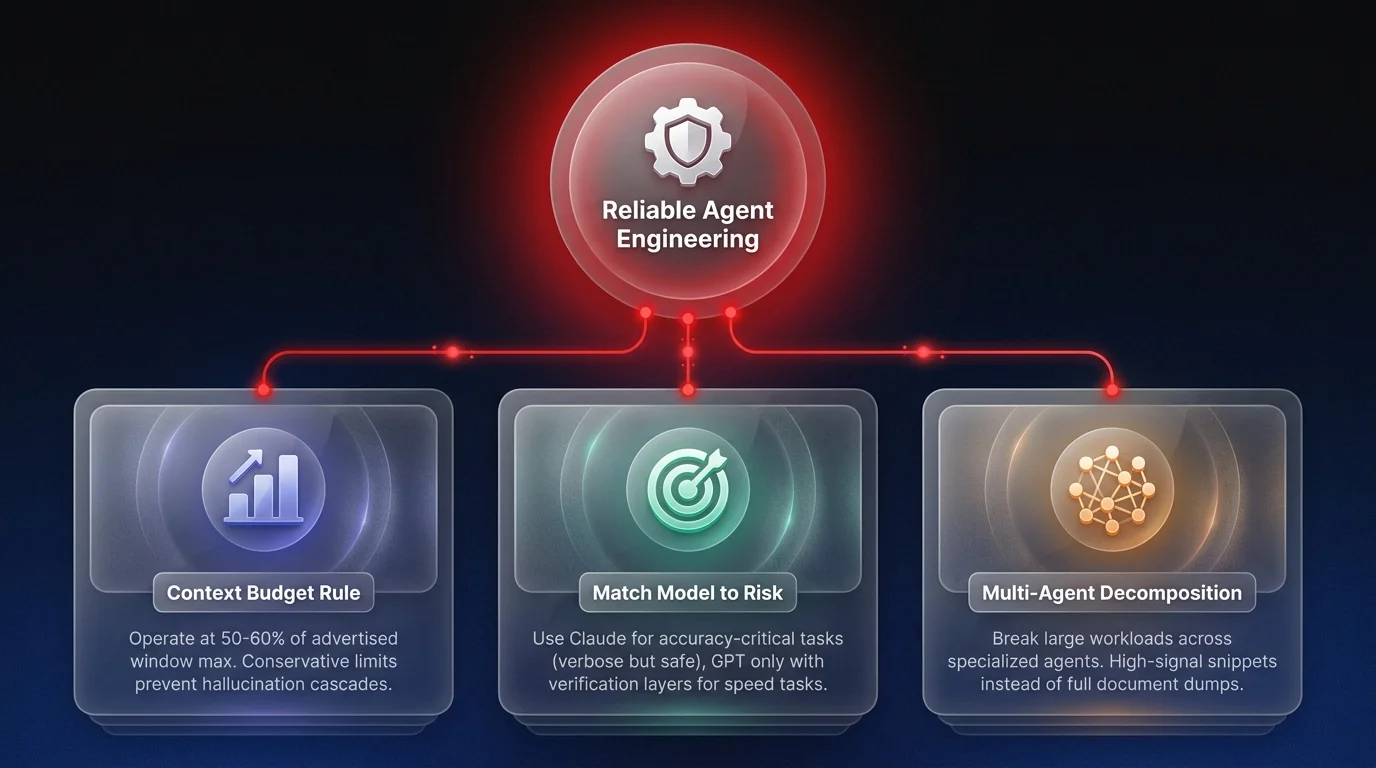
First, acknowledge that the 'effective context' is often 50-60% of what's on the spec sheet. If you're building critical infrastructure, you cannot rely on the marketing numbers. I trust Claude up to about 60% of its window before I start seeing that verbose degradation. For GPT, you need to be even more conservative because the failure is harder to detect programmatically.
Second, you need to match the model's personality to the task risk. If accuracy is existential - like in code generation or financial data - you might want to avoid models that fail with high confidence. This is why I've been shifting my coding agents towards Claude for software development workflows. I'd rather deal with extra verbosity that I can parse out than a confidently wrong answer that breaks the build.
Third, orchestrate your AI agents to reduce context load. Instead of dumping the whole codebase into one prompt, break it down. Use high-signal snippets. The goal isn't to see how much data you can cram in; it's to see how much clarity you can maintain.
The game has changed. We aren't just prompt engineers anymore; we're psychologists for these systems. If you want ownership over your AI outcomes, you need to anticipate these breakdowns before they happen. Don't let the model's confusion become your business problem.
Building reliable AI agents isn't about picking the model with the biggest number on the box. It's about understanding nuance and orchestration. At Ability.ai, we build secure, high-performance agent architectures that account for these degradation patterns. If you're ready to move beyond the hype and build systems that actually work, let's talk.
Building reliable systems
At Ability.ai, we build secure, high-performance agent architectures that account for these degradation patterns.