
Agent self-correction loops are AI workflow patterns where an agent generates output, evaluates it against defined quality criteria, and regenerates until the result meets the standard — without human intervention. Instead of treating AI as an autocomplete that delivers a first draft for humans to fix, self-correction loops shift quality control responsibility to the agent itself. I recently tested this with my agent, Corbin: I told him to generate diagrams and inspect them with his own vision capabilities — only showing me the ones that made logical sense. He caught errors I would have had to fix myself. The game has changed from generation to judgment.
Let's break down what actually happened
Let's break down what actually happened. I needed a set of technical diagrams for a presentation. Usually, this is a painful back-and-forth process. You ask for a chart, the AI gives you something with hallucinated text or weird shapes, and you spend the next hour iterating prompts to fix it.
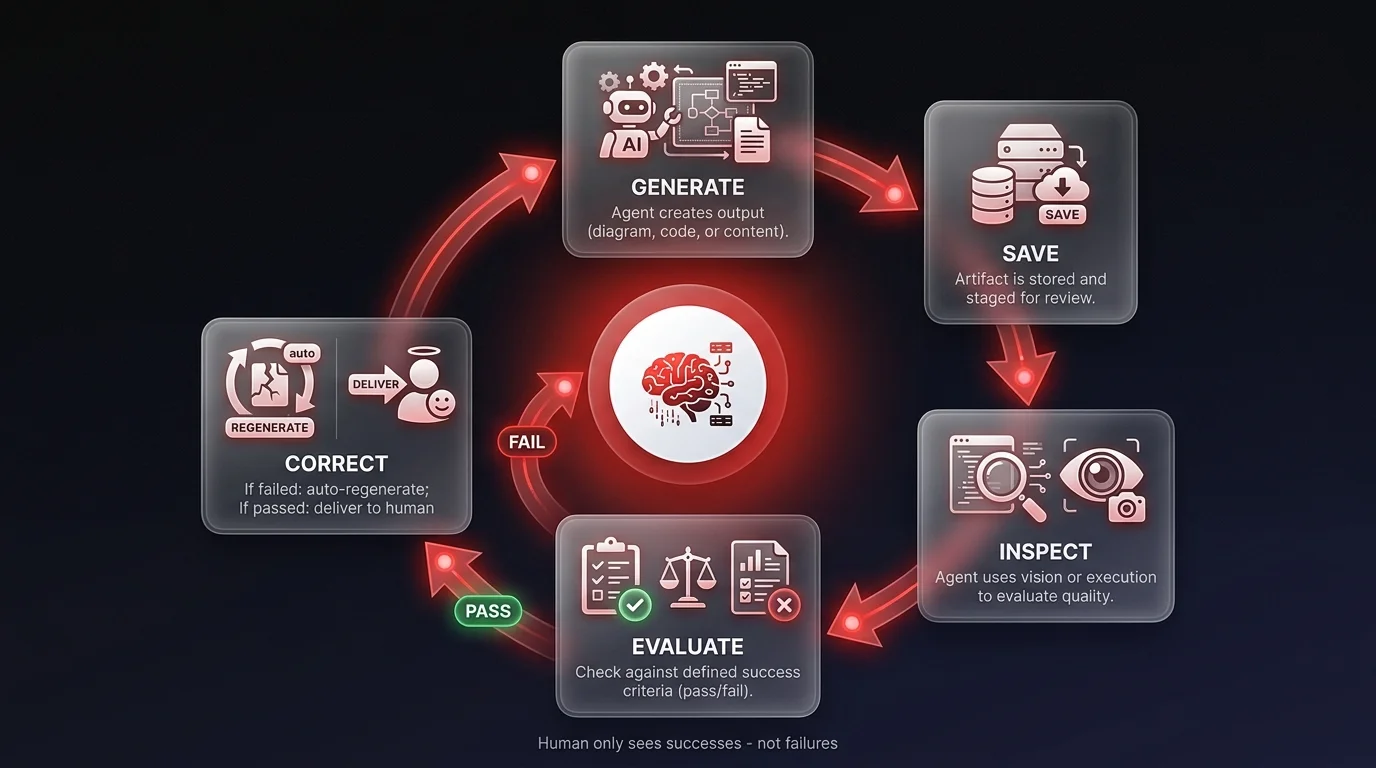
Instead of that grind, I orchestrated a self-correction loop. I instructed my agent, Corbin, to use a tool called 'Nana Banana' to generate the diagrams. But here is the radical part - I added a visual inspection step. I told him: 'Generate the image, save it, look at it with your vision capabilities, and verify it creates a logical flow.'
It wasn't perfect immediately. In one instance, Corbin generated a chart with duplicate boxes that cluttered the flow. In a standard workflow, that's where I would step in to micro-manage the fix. But because I gave him ownership of the quality control, he identified the redundancy himself. He saw the duplicate boxes, realized they violated the logic of the chart, and regenerated a corrected version.
I didn't see the failure; I only saw the success. This is what I mean when I talk about agentic workflows. We are moving beyond simple text generation into visual judgment. The AI isn't just a creator anymore; it's a critic. By the time the work reached my desk, the obvious errors were already gone. That is high-signal work.
This shifts the paradigm
This shifts the paradigm of how we build AI systems. The question isn't 'Can the AI write this?' The question is 'Can the AI judge if this is good?'
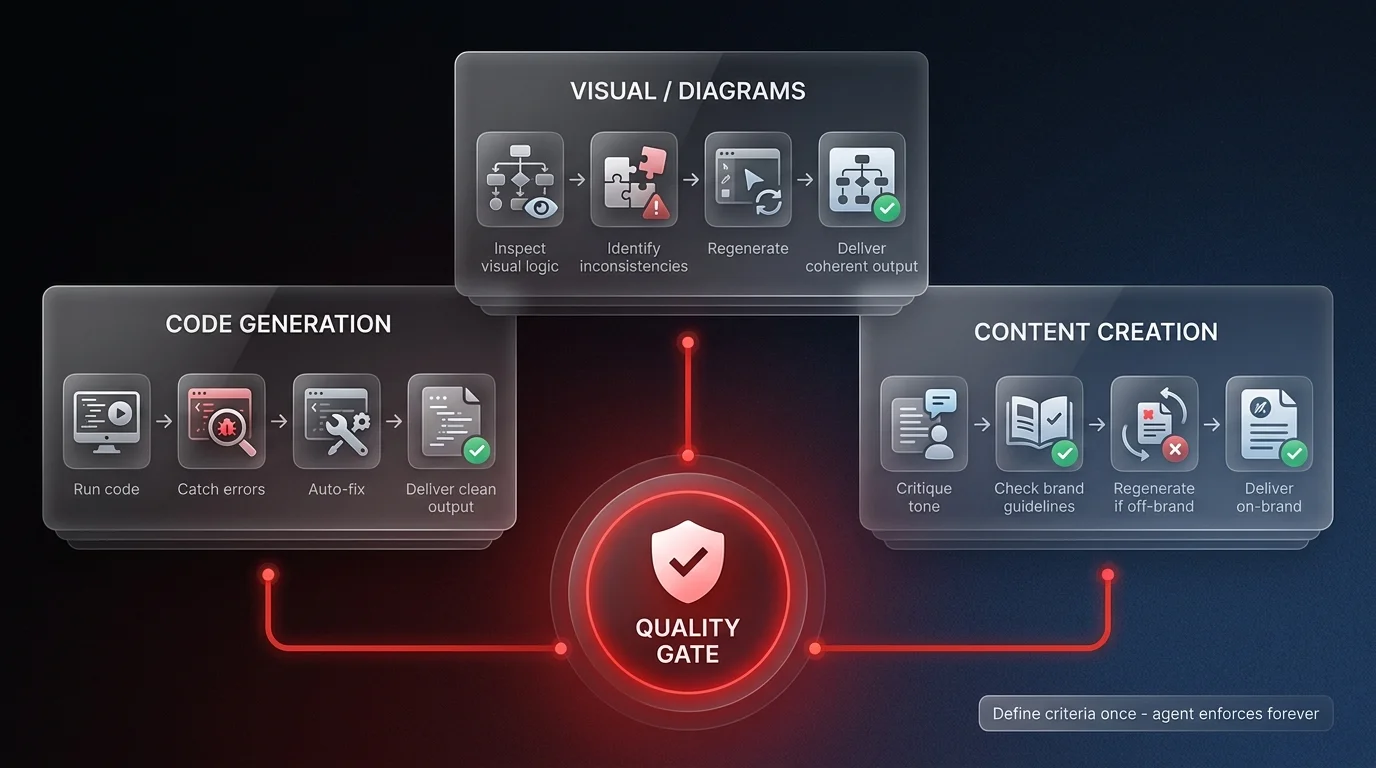
To get this level of output, you need to stop writing prompts and start orchestrating systems. You need to give your agents permission to reject their own work. When you build an agent, define the success criteria explicitly. Tell it what failure looks like.
For example, if you're generating code, the agent should run it and fix the bugs before showing you the snippet — a foundational principle in software development automation. If you're generating content, it should critique the tone against your brand guidelines before you read a single word. In my case, it was visual - checking if a diagram made sense.
Surprising to many, modern models are actually quite good at this visual judgment. They can spot inconsistencies that simple code checks might miss. This allows you to amplify your capabilities significantly. You aren't just one person using a tool; you are a creative director managing a junior partner who cleans up their own mess.
Stop accepting the first draft. Force your autonomous agents to iterate until they meet your standard. That is how you get radical operational leverage.
Are you still manually fixing your AI's mistakes? It's time to stop babysitting and start building autonomous systems that own their output. At Ability.ai, we orchestrate agents that handle the entire loop - from creation to critique to final delivery. Let's talk about how to amplify your workflow with agents that actually have judgment.