
AI coding agents are autonomous systems that generate, validate, and merge code at machine speed - replacing the human-centric pull request workflow. They expose a fundamental flaw in modern CI/CD: pipelines built for one or two diffs per week cannot handle thousands of concurrent machine-generated commits.
For the past decade, organizations have optimized their development lifecycle around human limitations. Now, as AI coding agents make code generation remarkably cheap and continuous, the very systems designed to protect codebases are shattering under the weight of machine speed.
Research into the engineering practices at the absolute forefront of development - observing how highly technical teams at organizations like Vercel, Zed, and Ramp operate - reveals a stark reality. Traditional CI/CD is practically dead in an agent-first world. The transition from monolithic AI tools to microservice-based autonomous agents is flooding repositories with thousands of concurrent, short-lived branches, making human review mathematically impossible.
CTOs and engineering leaders must now confront a critical architecture decision. Adapting to this shift requires moving away from delayed human feedback loops and adopting stateful, continuous compute infrastructure. Here is why the conventional pull request is obsolete, and how organizations must architect their systems to govern the next wave of synthetic engineering labor.
How AI coding agents collapse human-centric infrastructure
To understand why AI coding agents break existing pipelines, we have to look at the latency inherent in how software is validated today.
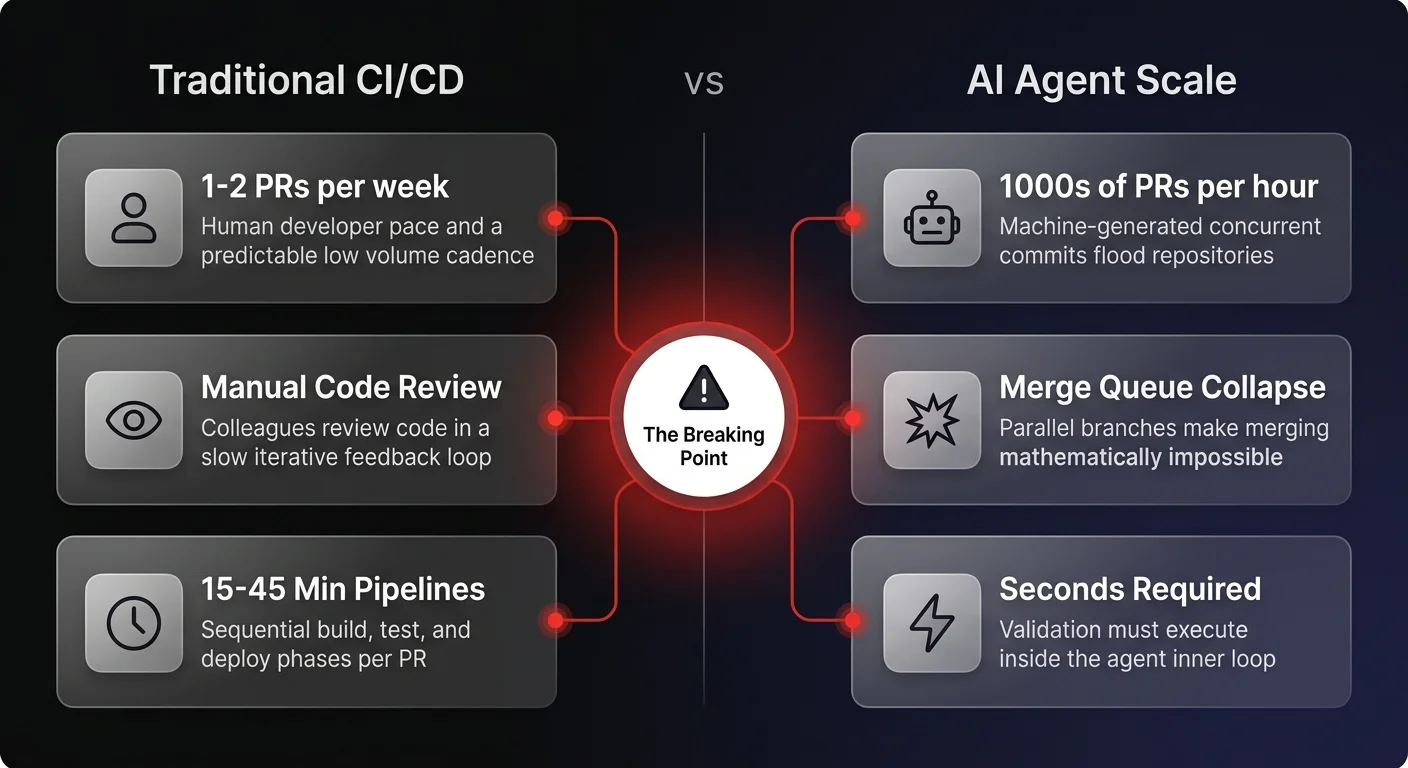
Historically, a human developer submits one or two diffs a week. These pull requests (PRs) initiate a well-worn path: colleagues take time to review the code, GitHub actions run build, test, and deploy steps, and the developer iteratively addresses failed test cases. The entire CI/CD pipeline, from local caches to merge queues, was built to accommodate this predictable, low-volume cadence.
At agent scale, this infrastructure collapses entirely. When autonomous agents operate using these exact same systems, they generate an exponential number of pull requests across an unlimited number of repositories. Teams already scaling AI agents through GitHub workflows have documented this spike in commits, alongside a massive divergence between lines of code added versus deleted.
When an agent attempts to pull the same codebase in a thousand different directions simultaneously through short-lived branches, merging these versions becomes a chaotic, unmanageable process.
The problem isn't just volume - it's the fundamental incompatibility of the PR itself. The pull request was designed as a discrete handoff for delayed human feedback. It assumes that a reviewer will eventually look at the code, provide notes, and send the developer back into a slow, methodical loop. When you replace the human developer with a machine capable of instantaneous iteration, forcing it to wait for human bottlenecks neutralizes the value of the automation.
Merge queues as high-performance ledgers
As the rate of change increases dramatically, the act of merging code begins to look less like a collaborative human review and more like a high-performance database problem.
In a highly autonomous environment, your Git repository acts as a single ledger. Every time a change needs to be committed, the system essentially has to lock the database to ensure serialization. When changes are submitted by humans, the time between these locks is vast. When thousands of machine-generated commits are vying for inclusion simultaneously, the opportunity to merge shrinks to milliseconds.
Industry leaders like Mitchell Hashimoto, the former founder of HashiCorp, have pointed out that platforms like GitHub must evolve to serve AI and agentic users first, or they will simply fail to function. The infrastructure required to process this volume necessitates ingress shaping, aggressive rate limiting, and hardware/software co-design where the cache itself becomes the orchestration layer.
If tests take fifteen to forty-five minutes to run, the entire inner loop of the agent is stalled. Validation must move directly into the agent's workflow, executed in seconds rather than minutes, fundamentally shifting how we think about CI/CD.
The new architecture: stateful continuous compute for AI coding agents
To survive this transition, engineering teams are abandoning the concept of the pull request entirely. The new workflow starts with intent and a plan - a specification written in a Linear ticket or a Slack message - which is then passed to an agent harness.
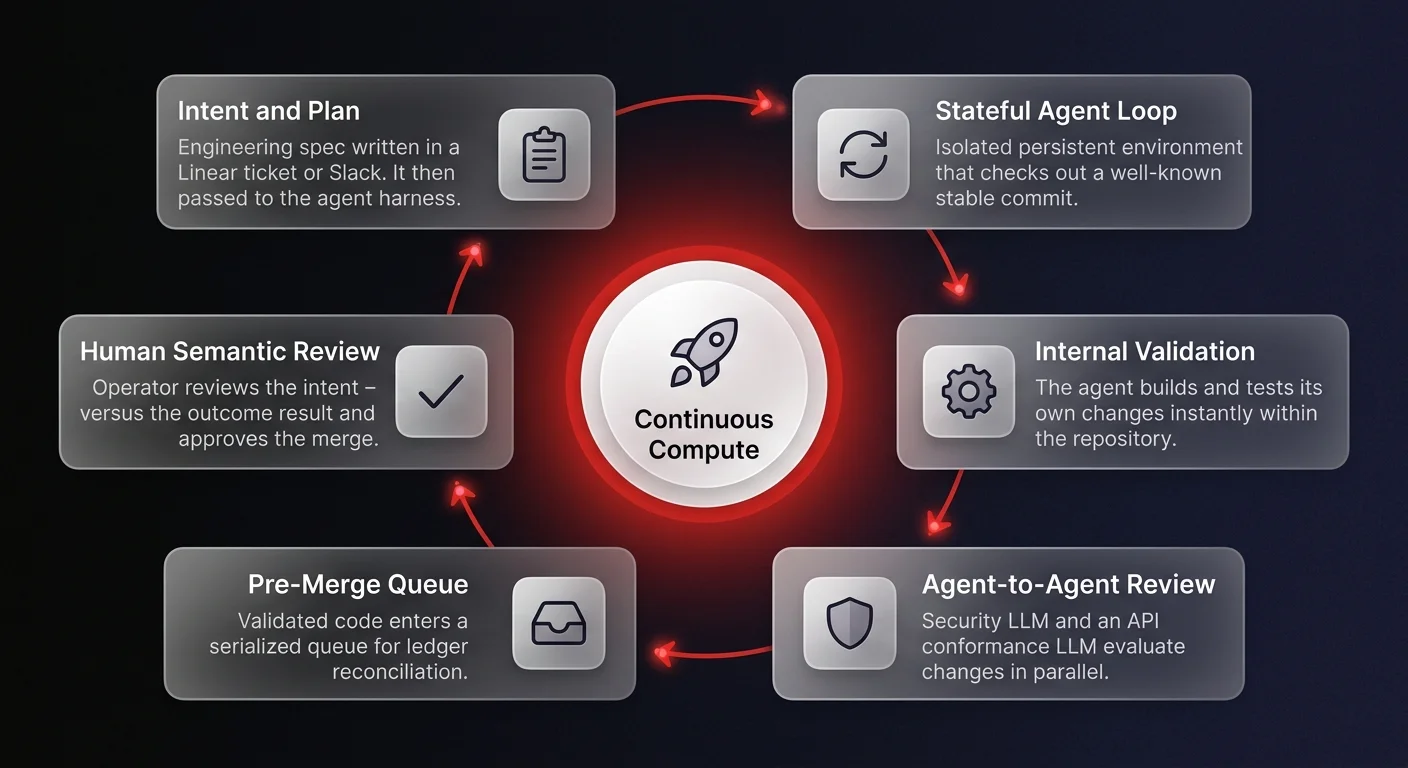
This agent enters an isolated, stateful loop. It checks out a well-known commit, begins writing code, and immediately executes internal validation. It builds and tests its own changes using the assets existing within the repository.
However, for this to work, agents cannot start from scratch every time a loop initiates. They require continuous, stateful environments with persistent memory. Dropping an agent into a stateless, cold environment forces it to re-establish context, severely delaying the compute cycle and wasting expensive inference cycles.
This is where the architecture of the agent layer becomes paramount. Agents are company infrastructure, not just workflow glue or localized API scripts. They require production-grade hosting that is scheduled, audited, and recoverable.
Organizations building autonomous AI agent workflows are already proving this model works - achieving 25x deployment frequency increases by treating agents as persistent infrastructure rather than ephemeral tools.