Scaling AI agents is the practice of moving autonomous AI systems from isolated prototypes to reliable, governed enterprise deployments that handle millions of operations weekly. GitHub's MCP server - processing roughly 8 million tool calls per week - reveals the critical patterns every operations leader needs to master.
When organizations begin scaling AI agents across their operations, they quickly collide with a hard reality - the gap between a neat local experiment and a reliable enterprise deployment is massive. Industry data from the development of GitHub's Model Context Protocol (MCP) server exposes the hidden complexities of moving AI from prototype to production.
For operational leaders caught between the sprawl of ungoverned Shadow AI and the sluggish pace of massive consulting projects, these technical scaling challenges hold vital strategic lessons. By analyzing how one of the world's largest developer platforms optimizes context windows, secures access tokens, and orchestrates complex system operations, businesses can build highly reliable sovereign AI agent systems that drive actual outcomes without introducing unacceptable risks.
Why scaling AI agents fails when you add more tools
There is a common misconception in enterprise AI that giving an agent access to every possible tool and system will make it more capable. The data proves the exact opposite.

When agents are loaded with too many tools, their reasoning degrades. They become forgetful, confused, and prone to hallucination. Early in GitHub's MCP journey, exposing agents to over 100 discrete tools for repositories, pull requests, actions, and projects rapidly blew out context windows and degraded the agent's core performance. This aligns with earlier industry research demonstrating that excessive context degrades LLM reasoning quality rather than enhancing it.
The solution requires strict constraint and curation. By trimming default configurations, focusing tools on general use cases, and clustering CRUD (Create, Read, Update, Delete) operations, context load can be reduced by nearly 49%. Furthermore, stripping unnecessary metadata from tool outputs - such as aggressively tailoring the data returned by a "list pull requests" command - can eliminate over 75% of output token consumption.
For business operations, this validates a solution-first model over open-ended AI experimentation. Instead of overwhelming an AI with access to your entire tech stack, deployments should begin with a tightly scoped starter project. By defining a fixed scope and a specific business outcome, you naturally constrain the agent's toolset, preserving its reasoning capabilities and ensuring immediate, reliable value.
Server-side orchestration: hiding complexity from the LLM
One of the most profound lessons in scaling AI agents at the enterprise level is recognizing what an LLM should not do. Large Language Models are exceptional reasoning engines, but they are relatively fragile workflow orchestrators.
When an agent must navigate complex operational logic - like making five sequential API calls to figure out repo permissions before committing code - failure rates spike. Agents do not inherently know which systems they have write permissions for, leading to inevitable hallucinations and failed actions.
The architectural fix is shifting this complexity away from the agent and onto the server. By encoding the "agent intent" on the server side, a single request from the AI can autonomously trigger a robust, multi-step execution handled by deterministic software. This approach slashes round trips between the agent and the server, preserves the context window, and significantly boosts reliability - ultimately driving tool success rates above 95%.
This maps perfectly to how modern sovereign AI agent systems should be designed. Rather than relying entirely on the LLM to navigate fragile API endpoints, organizations should utilize battle-tested workflow automation tools (n8n, Make, or custom pipelines) for process orchestration. The LLM handles the cognitive reasoning, while the orchestration layer handles the deterministic integration logic. This separation of concerns is exactly what makes visual orchestration more reliable than terminal-based agent workflows.
The Shadow AI security crisis when scaling AI agents
The utility of autonomous agents currently sits in direct conflict with enterprise security. In the wild, AI setups are frequently insecure by default. Users often rely on plain text access tokens that are stored in easily accessible locations, are long-lived, and remain dangerously overprivileged.
Security researchers have repeatedly demonstrated prompt injection and data exfiltration attacks. If an agent has sweeping access to a company's internal code or customer data, a malicious prompt can trick the agent into exposing that private data. The lethal trifecta of agent security - prompt injection, autonomous tool execution, and overprivileged access - makes ungoverned Shadow AI a ticking time bomb for enterprise IT.
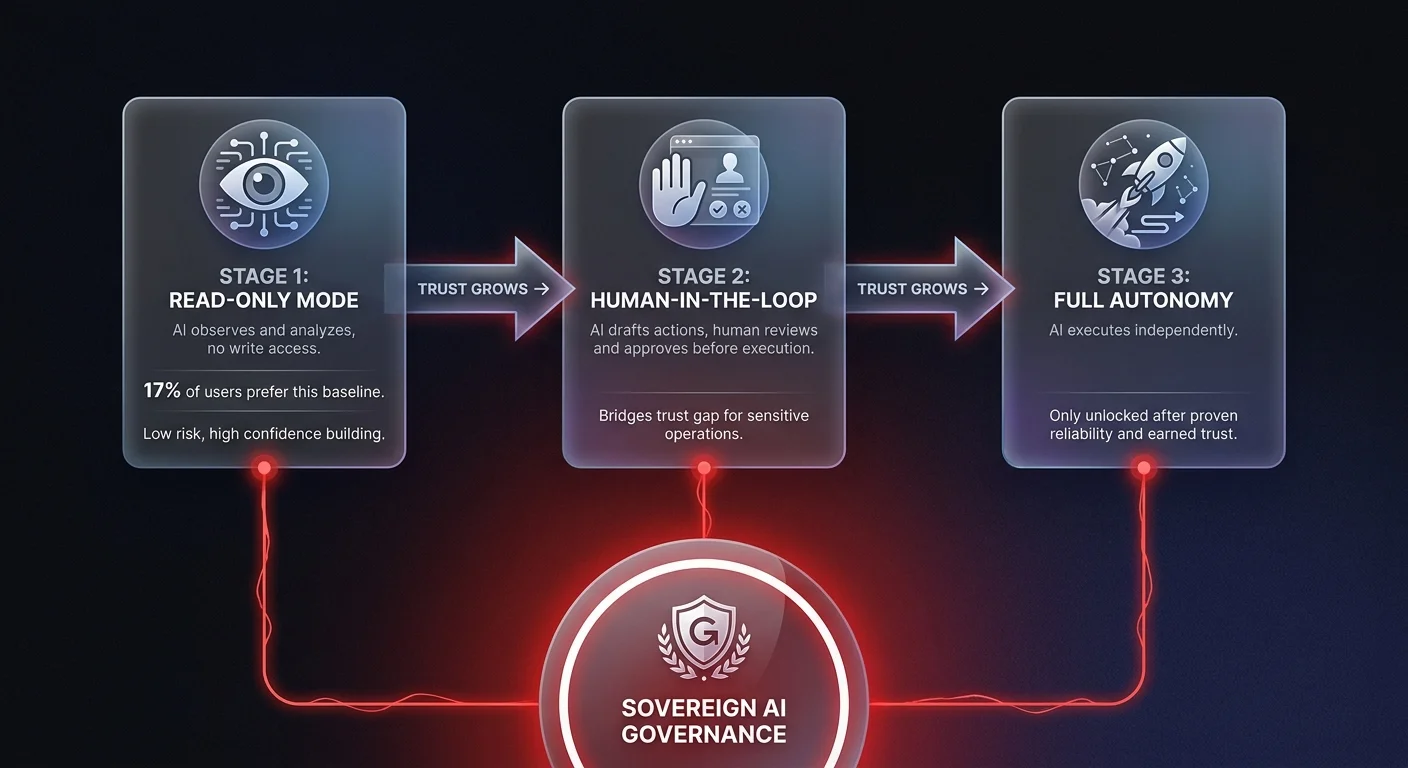
Scaling operations teams cannot allow employees to hook random AI chatbots up to their core systems using personal tokens. Securing this infrastructure requires a centralized, governed approach. Solutions include supporting dynamic token scoping, where tools are immediately filtered down based on the exact permissions of the provided token, and step-up authentication that interactively asks the user to authorize new permissions mid-workflow rather than silently failing or operating with permanent god-mode access.
Deploying sovereign AI means taking back control of these integrations. Whether utilizing robust cloud infrastructure or maintaining strict local data boundaries, organizations must own the infrastructure where their tokens and tools reside. See how mid-market companies are implementing governed AI agent integration without the Shadow AI sprawl.