
AI context rot is the gradual performance degradation that occurs when an AI agent's context window becomes overloaded with accumulated, low-signal information. Unlike model bugs, context rot happens when changelogs, conversation histories, and documentation grow unchecked — drowning the model in noise rather than signal. While vendors hype up massive context windows, feeding your AI the entire history of a project is a guaranteed way to break it. To build agents that scale, you need to stop hoarding context and start curating it.
Here's what I mean by context rot
Here's what I mean by context rot. As you iterate on a project, your changelogs, roadmaps, and conversation histories grow. Intuitively, you think providing all this history helps the model 'understand' the project better. But the game has changed. The more data you feed it, the more confused it becomes. It becomes difficult to manage and much more prone to mistakes.
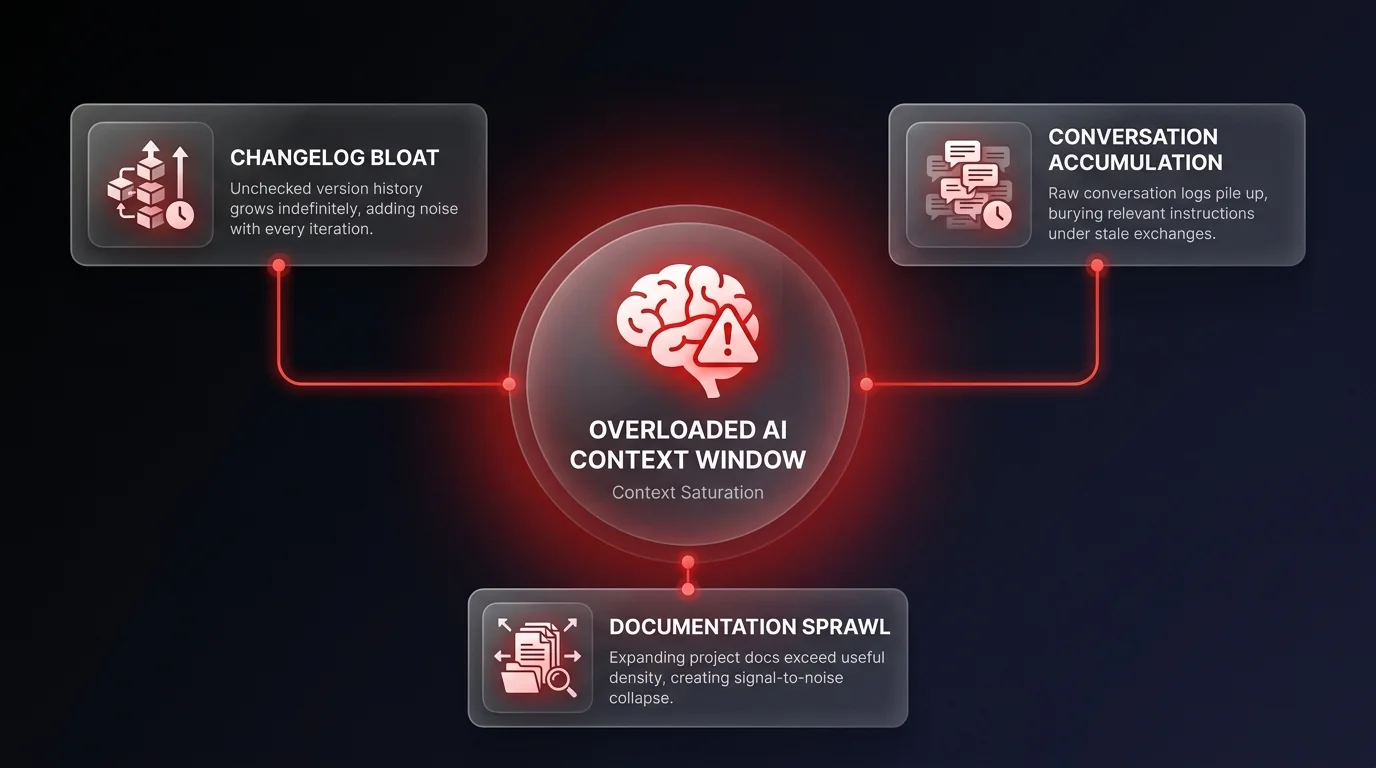
I recently hit this wall during a multi-phase implementation. My changelog had ballooned, and the agent started losing the plot. It wasn't a capability issue; it was a signal-to-noise issue. I had to hit the brakes, stop the build, and radically rethink how we were feeding information to the model.
Most developers treat context like a hard drive - a place to store everything. But you need to treat it like RAM. It's a finite, volatile resource. When you overblow your changelogs or documentation, you aren't giving the AI more information; you're drowning it in noise. The status quo of 'dump everything into the prompt' is dead. If you want high-performance agents, you have to take ownership of what goes into that window.
So, how do we solve this?
So, how do we solve this? We switch to a mode of active curation. The logic is simple but powerful: keep the most recent logs detailed, and summarize the rest.
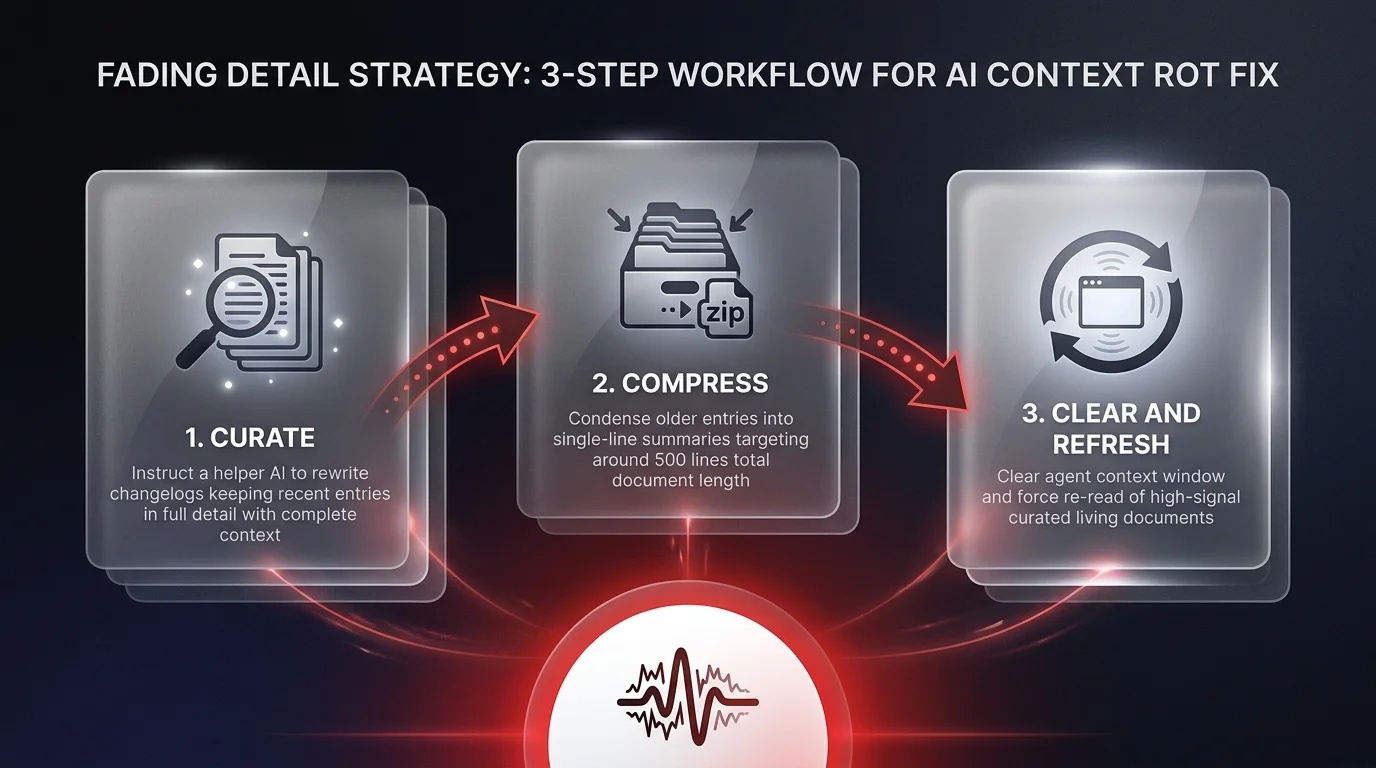
I use a 'fading detail' strategy. I instruct a helper AI to rewrite our project changelog with a specific rule: keep full details for the most recent updates, but condense older entries into single-line summaries. The goal is to keep the overall length manageable - say, around 500 lines. This ensures the model has the immediate context it needs to execute the next task without getting bogged down in ancient history.
It's about maintaining 'living documents' that evolve. Instead of a static archive that grows forever, your documentation should breathe. Old context gets compressed; new context stays fresh — a pattern that keeps autonomous agents performing reliably across weeks-long projects.
And don't forget the operational side. I frequently use the 'clear' command in my agent's terminal. This isn't just about tidying up; it forces the agent to drop its accumulated conversational baggage and re-read these newly curated, high-signal documents. This is how you orchestrate success - by amplifying the signal and aggressively cutting the noise.
Context is the new code. If you aren't managing it, it's managing you. At Ability.ai, we build agent architectures that handle this curation automatically, ensuring your systems stay smart no matter how long the project runs. Ready to stop fighting context rot? Let's build something that scales.