
Structured output for LLMs is the practice of enforcing a strict JSON schema on AI responses — transforming probabilistic language models into reliable, automatable components of your software architecture. If you're building actual software, prose is garbage: it's unstructured, unpredictable, and impossible to parse programmatically. You need to stop asking for text and start demanding structure. The question isn't how well your AI writes; the question is how well it integrates.
Let's break it down
Let's break it down. When you're building an AI agent to orchestrate complex tasks - like updating a CRM or triggering a payment - 'maybe' isn't good enough. You can't write code that parses a paragraph beginning with 'Certainly! Here is the information you requested.' That is high-noise, low-signal fluff.
The game has changed. We are no longer just prompting; we are engineering integration points. JSON acts as the bridge between the fuzzy, probabilistic world of LLMs and the deterministic, rigid world of your codebase. When you enforce a strict schema, you are essentially telling the model to stop being a creative writer and start being a data processor.
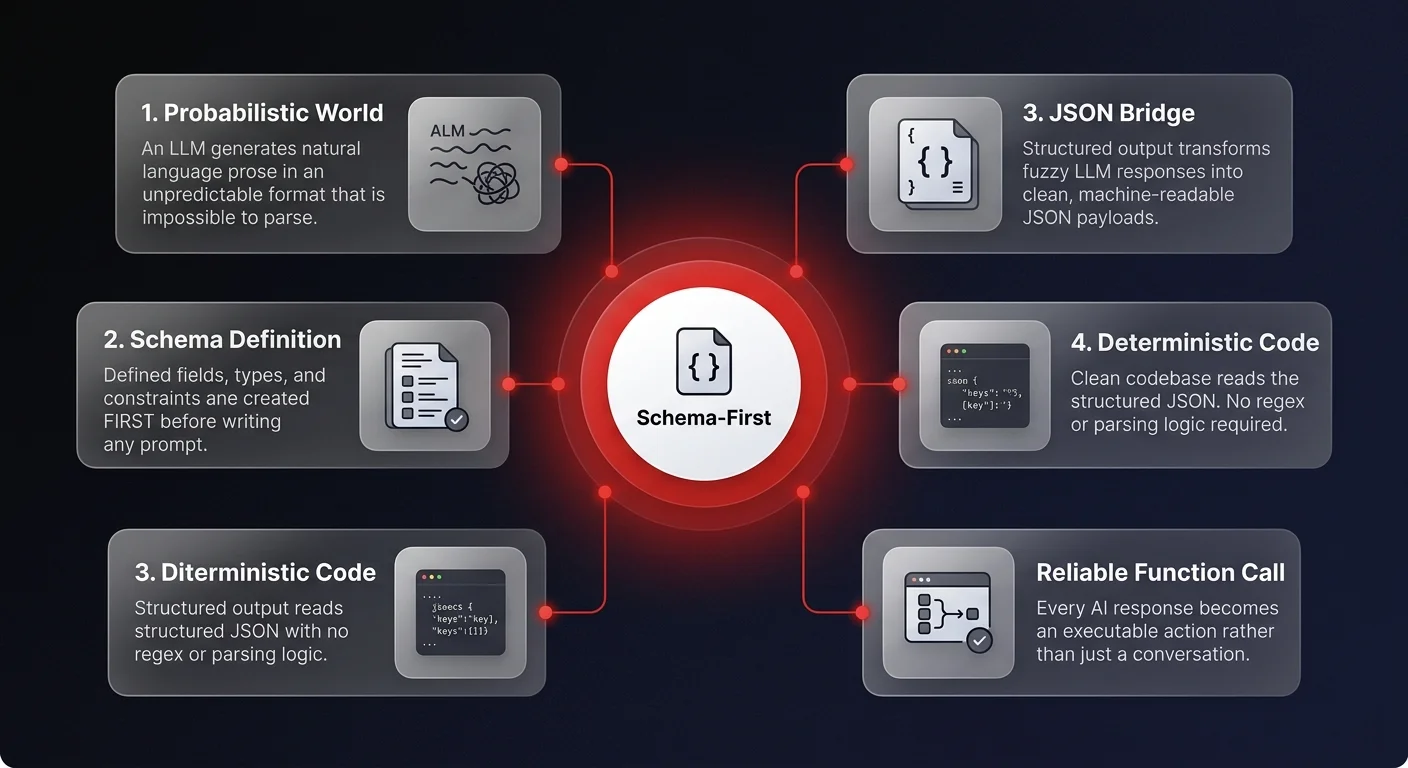
This is where the concept of schema-first design comes in. Instead of writing a prompt and hoping for the best, you define your output structure first. You define the fields, the types, and the constraints. You force the model to conform to your system's reality, rather than trying to adapt your system to the model's whims. This shift is radical but necessary. It turns a probabilistic guess into a reliable function call.
Without structure, intelligence cannot be easily automated. If you want to scale your operations, you need to treat the LLM as a component in your stack, not a magic box that talks to you — which is the core engineering principle behind how we build AI software automation for production environments.
So how do you actually implement this?
So how do you actually implement this? It starts with owning the output format. Don't just ask for a list; provide a JSON schema that defines exactly what that list looks like. Modern LLMs are incredibly good at adhering to these schemas if you are explicit.
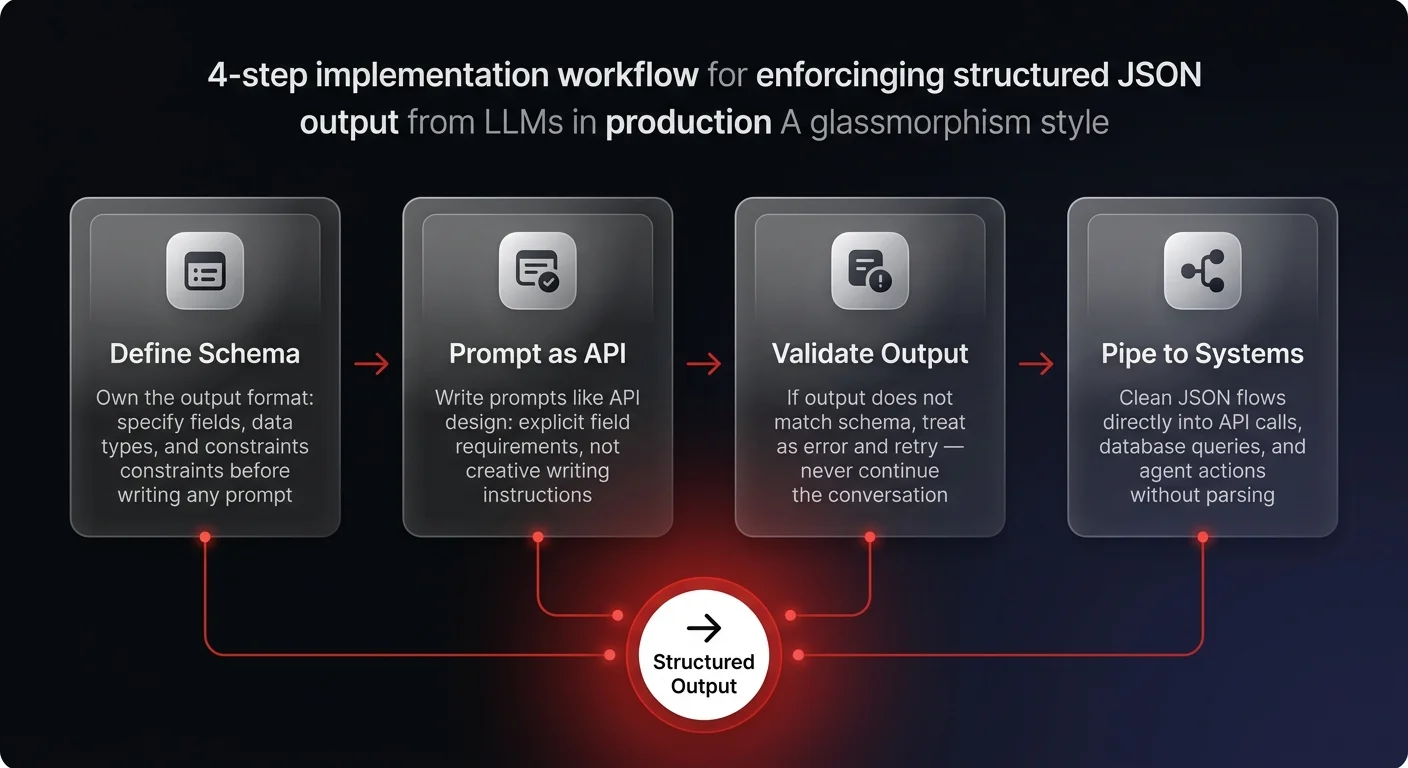
The reality is that reliable agents depend on predictable inputs and outputs. When you receive a clean JSON object, you can immediately pipe that data into an API request or a database query without complex parsing logic or regex nightmares. You amplify the utility of the model because it's no longer just generating text — it's generating executable actions, the same pattern that powers every autonomous agent we build at Ability.ai.
Stop treating prompt engineering like creative writing. Treat it like API design. Define your interfaces. Validate your outputs. If the model returns data that doesn't fit the schema, you treat it as an error, not a conversation. This creates a feedback loop that ensures stability.
Once you make this mental switch, you stop building toys and start building systems that can scale. That is how you win at business automation. You don't just want an answer; you want a payload.
Building high-performance AI agents requires more than just good prompts - it requires robust engineering discipline. At Ability.ai, we specialize in orchestrating these exact kinds of structured, reliable workflows. If you are ready to move beyond chatbots and build agents that actually drive business value, let's talk.