
A proprietary data moat is the competitive strategy of building defensible AI businesses through exclusive access to domain-specific datasets that cannot be replicated by competitors using publicly available data. In an era of commoditized LLMs where any company can access the same models, your data — not the model — is your competitive advantage. Companies that own longitudinal, vertical-specific datasets build AI systems with accuracy and reliability that generic API wrappers simply cannot match.
The proprietary data moat
The proprietary data moat is dramatically missing from most AI strategies I see today. Founders are still chasing volume - 'Big Data' - thinking that feeding an ocean of generic information into a model creates value. It doesn't. It just creates noise. Real value comes from deep verticalization and what we might call 'Long Data'.
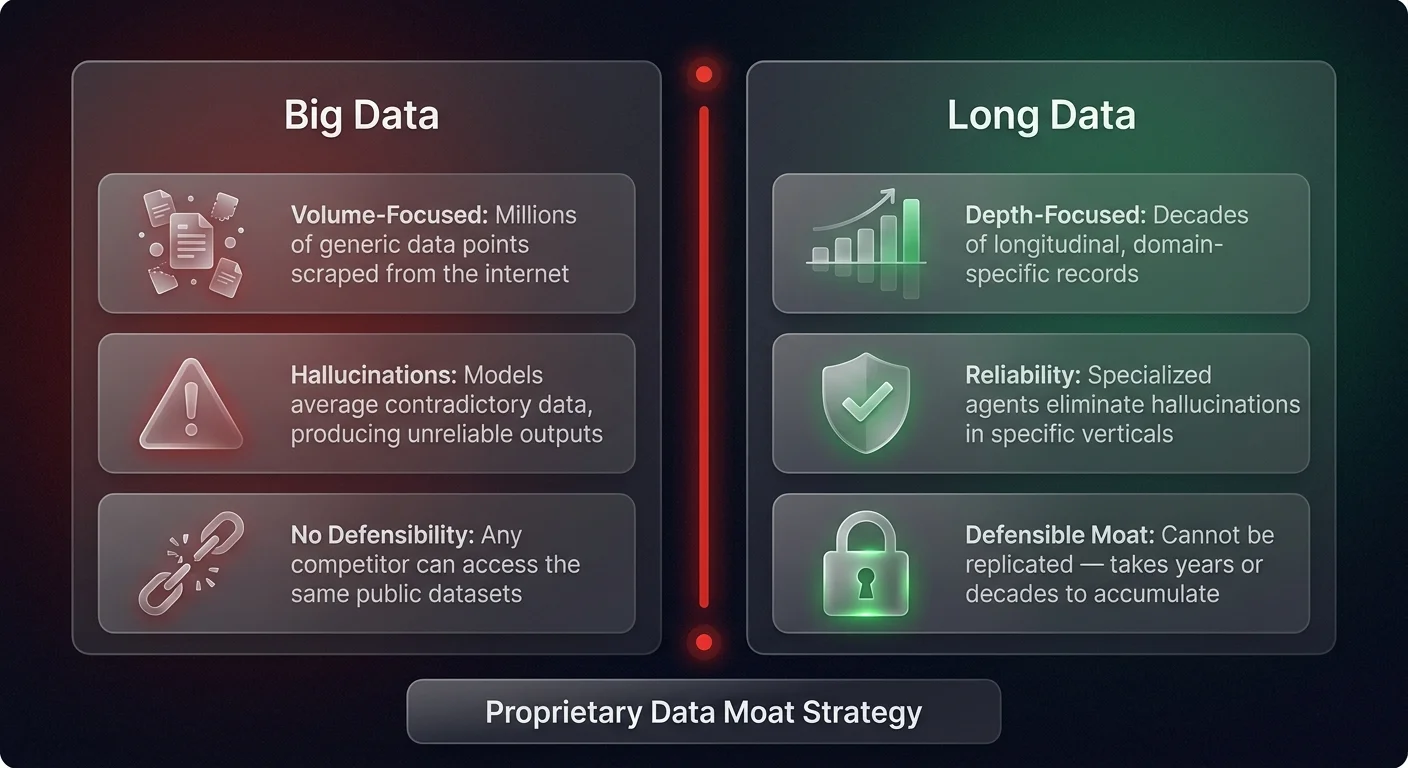
Take digital health as an example. A generalist model trained on the entire internet can give you generic advice about weight loss. But it hallucinates because it's averaging out millions of contradictory data points. Compare that to a specialized player focusing specifically on obesity and GLP-1 outcomes. They aren't just scraping the web. They are collecting longitudinal patient data over decades - tracking specific markers, side effects, and long-term results for a specific demographic. That is a moat. You can't replicate that by simply API-calling OpenAI.
Generalist models train on oceans of data, which leads to hallucinations. Specialized agents trained on 'quality via data' in specific verticals - whether that's legal, finance, or niche healthcare - eliminate those hallucinations. This isn't about scraping more data. It's about owning the right data. We need sometimes decades, not years, to create this proprietary moat. If you can't point to the unique dataset you own, you don't have a product.
Radical verticalization
So what does this mean for you? You need to stop thinking broad and start thinking deep. The era of the 'AI for everything' platform is over before it really began. The winners of the next cycle will be the ones who radically verticalize.
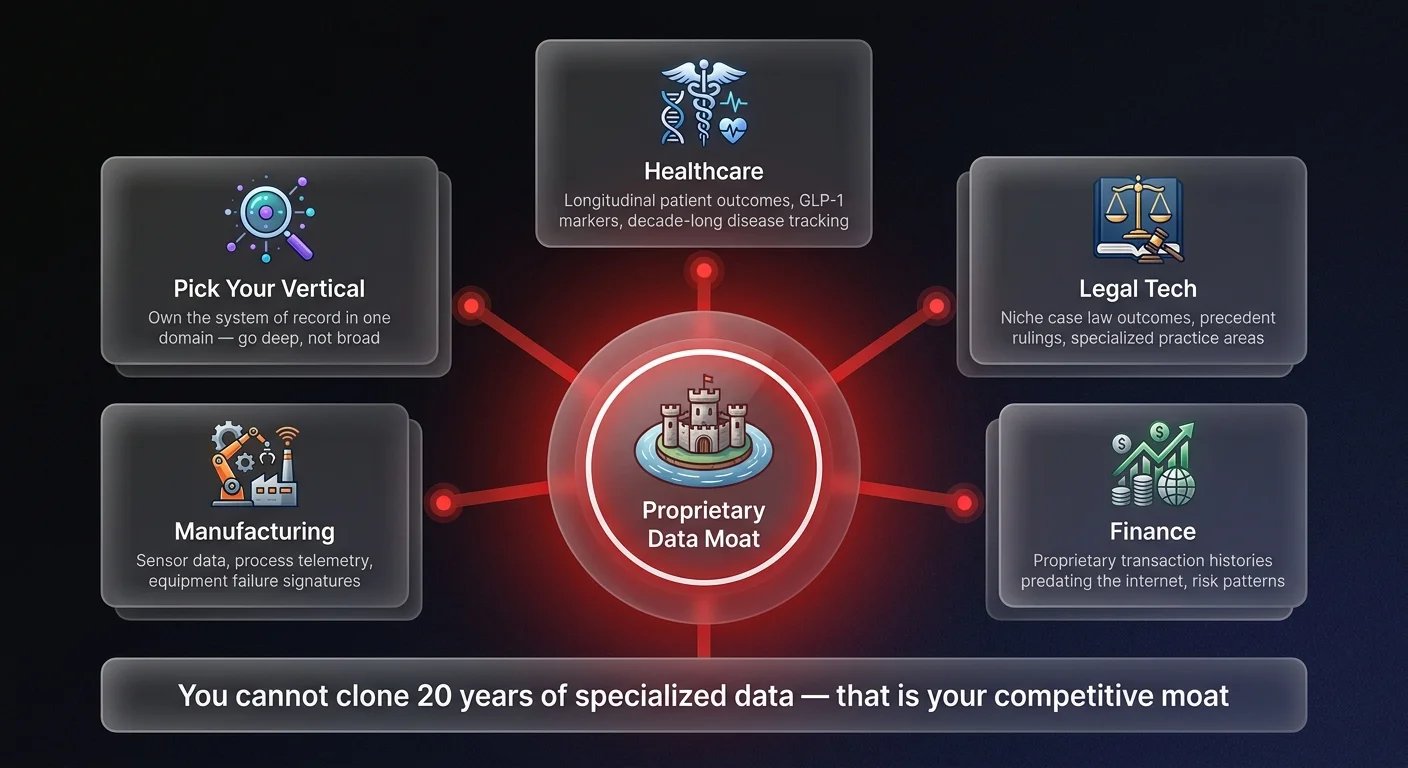
Instead of trying to solve every problem for every user, pick a specific vertical where you can orchestrate a system of record. In legal tech, this means having the deepest repository of specific case law outcomes for a niche practice area. In finance and procurement, it means having proprietary transaction data that predates the internet. This is how you flip the script on incumbents and generalist AI models.
When you build AI agents on top of this high-signal, vertical-specific data, you create something magical. You get reliability. You get trust. And most importantly, you get defensibility. A competitor might be able to clone your UI or prompt engineering in a weekend. But they cannot clone twenty years of specialized disease outcome data.
Ownership is the keyword here. You must own the data layer. Don't rely on public datasets that everyone else is using to train their models. Build your own. Curate it. Clean it. That is the hard work that creates value. The status quo of lazy wrappers is dead. The future belongs to those who do the hard work of vertical integration.
Building defensible moats
The game has changed. You can either be a commodity wrapper or a vertical powerhouse. At Ability.ai, we help businesses orchestrate AI agents that leverage deep, proprietary data to solve real problems - not just chat about them. Let's talk about how to build a defensible moat for your specific use case.