AI agent governance is the practice of centralizing oversight and control of all AI agents, tools, and workflows across an enterprise - using registries, gateways, and standardized deployment blueprints to eliminate shadow AI and scale automation safely. Organizations with mature AI agent governance transform fragmented, unmonitored experiments into observable, cost-controlled operational systems.
What happens when dozens of teams across three continents all build AI tools independently, each wiring up their own connections, reinventing their own security models, and deploying their own shadow infrastructures? You get total operational chaos. Operational leaders are recognizing that robust AI agent governance is no longer optional - it is the fundamental prerequisite for scaling artificial intelligence across the enterprise.
Without centralized oversight, fragmented AI experiments create immense security vulnerabilities, unpredictable operational costs, and maintenance nightmares. The solution lies in shifting from isolated, unmonitored AI deployments to governed agent infrastructure with data sovereignty and observable logic.
Amplifon, the world leader in hearing care solutions with over 20,000 employees and 10,000 stores across 26 countries, recently overhauled its AI strategy to combat this exact problem. By implementing a comprehensive governance program - complete with internal registries, centralized gateways, and standardized developer blueprints - they transformed fractured AI experiments into reliable operational systems.
Here is how global enterprises are architecting the next generation of governed AI systems, and how operations leaders can apply these frameworks to regain control of their AI initiatives. For a deeper look at the infrastructure layer beneath governance, see our overview of AI context infrastructure governance.
The shadow AI crisis: scaling risks and maintenance nightmares
As organizations push for rapid AI adoption, development teams often operate in silos. This decentralized approach creates immediate enterprise scaling problems. Operations and IT leaders find themselves facing three distinct challenges:
- Maintenance and operations: The lifecycle of Large Language Models (LLMs) is notoriously short. Models are frequently updated, deprecated, or experience outages. When isolated teams hardcode specific LLMs into their workflows, a single model deprecation can silently break critical business processes across the globe.
- Governance and compliance: Regulatory compliance requires a clear understanding of where and how AI is used within the organization. When teams build shadow agents, leaders lose the ability to audit data lineage, ensure security compliance, and catalog corporate AI assets.
- Redundant engineering: When developers are forced to repeatedly build authentication, cost-tracking, and deployment pipelines from scratch, they waste valuable engineering hours reinventing the wheel rather than focusing on core business logic.
To solve these problems, scaling companies must establish an operating model based on governance, platform standardization, and efficient factory deployment. This means building a single source of truth for all AI operations. The risks are compounded in organizations dealing with shadow AI governance crises - where ungoverned agents accumulate over months before leadership realizes the scope of the problem.
The tri-registry approach to AI agent governance infrastructure
To map and govern their entire AI ecosystem, forward-thinking organizations are building centralized registry systems. This architecture acts as the enterprise control tower, ensuring all AI components are visible, documented, and secure.
The most effective AI agent governance framework utilizes three distinct but interconnected registries: the MCP registry, the A2A registry, and the Use Case registry.
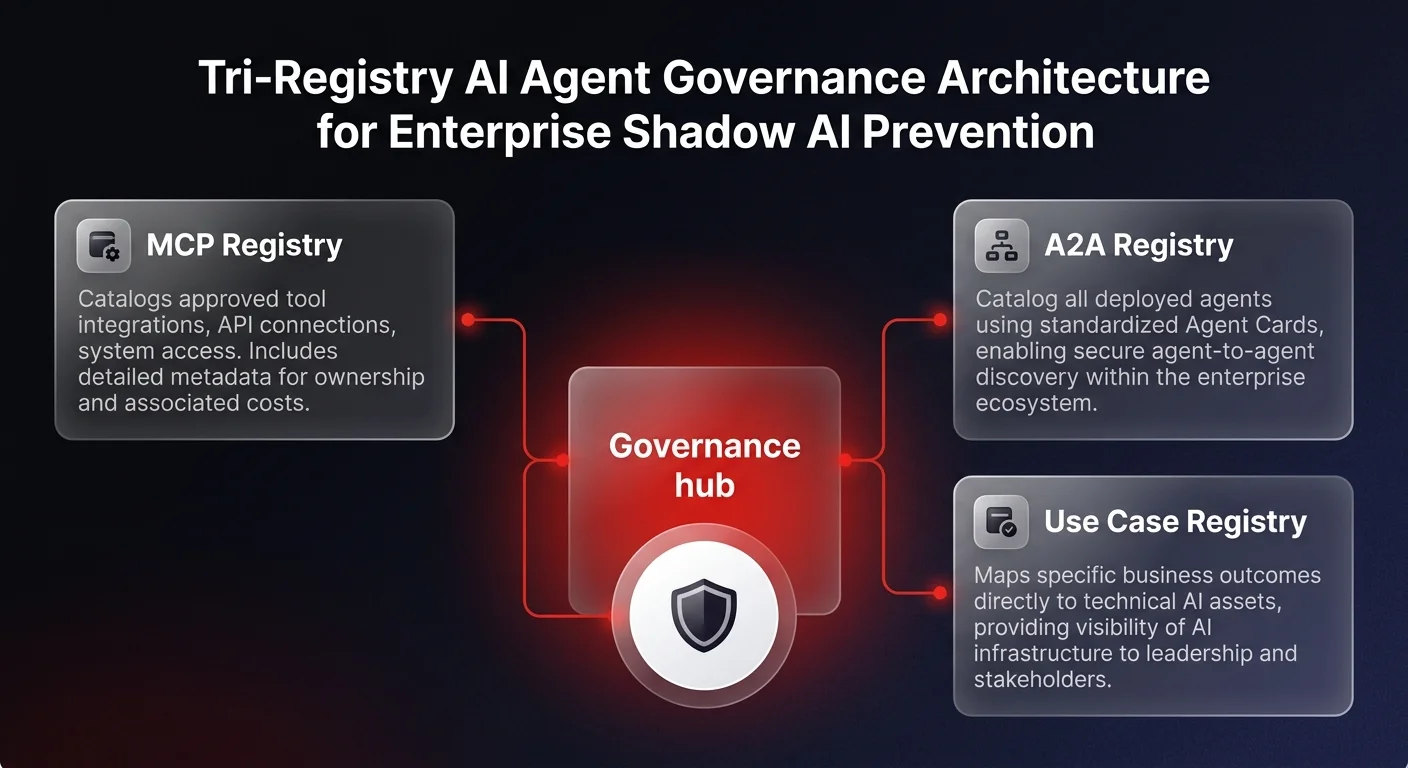
The Model Context Protocol (MCP) registry
The Model Context Protocol has emerged as the standard for connecting AI models to enterprise tools and systems. An enterprise MCP registry serves as the central catalog of all available tools and system integrations that an AI model is permitted to use.
Instead of teams building custom API connections for every new agent, they pull from a private, enterprise-grade MCP registry. This includes custom internal servers built for specific company systems, alongside a curated set of approved public servers.
Crucially, enterprise MCP registries enrich these tools with mandatory operational metadata, including ownership (which team maintains the server), environment (Dev, Test, or Production), authentication models (security mechanisms required), cost contribution (budget tracking linked to the server), and use case linkage (business applications actively using the tool).
The agent-to-agent (A2A) registry
Enterprise AI is rapidly moving away from isolated chatbots toward multi-agent systems, where specialized agents must discover and securely trigger one another. The A2A registry is a comprehensive catalog of all deployed agents within the organization, operating using standard "Agent Cards" - descriptive profiles that outline an agent's identity, endpoints, capabilities, supported modalities, and authentication requirements.
By integrating this registry with CI/CD pipelines, agent development becomes self-documenting. When an engineer deploys a new agent, its Agent Card is automatically published to the A2A registry, allowing other enterprise agents to discover and interact with it securely.
The use case registry
While the MCP and A2A registries handle technical infrastructure, the Use Case registry provides the critical business lens. This registry maps specific business outcomes - such as automated customer support or sales data extraction - to the exact technical assets powering them.
It connects the dots between the business problem, the AI models utilized, the specialized agents deployed, and the specific MCP tools accessed. This holistic view is what transforms a collection of technical tools into an observable, governed business operation.
Mapping the AI blast radius with object lineage
One of the most profound operational benefits of this tri-registry system is the ability to visualize object lineage.
Consider a common operational nightmare: an external AI vendor pushes a breaking update to a core LLM, or an internal database changes its authentication requirements. In an ungoverned shadow AI environment, diagnosing which business processes are broken requires days of frantic investigation.
With a connected Use Case registry, operations leaders have an immediate visual map of their "AI blast radius." If an LLM goes offline, the lineage view instantly highlights every agent, MCP server, and business use case affected. This enables rapid incident response, targeted maintenance, and seamless fallback routing to alternative models. Data sovereignty and observable logic ensure that the business controls the AI, rather than the AI controlling the business.
Controlling costs through a unified AI gateway
Beyond asset cataloging, organizations must implement strict access and budgeting controls. Allowing decentralized teams to hit LLM APIs directly inevitably leads to skyrocketing, untraceable token costs.
The solution is routing all AI traffic through a centralized AI gateway. This gateway provides a unified endpoint for all developers, abstracting the complexity of managing multiple AI vendors while enforcing rigorous enterprise constraints.
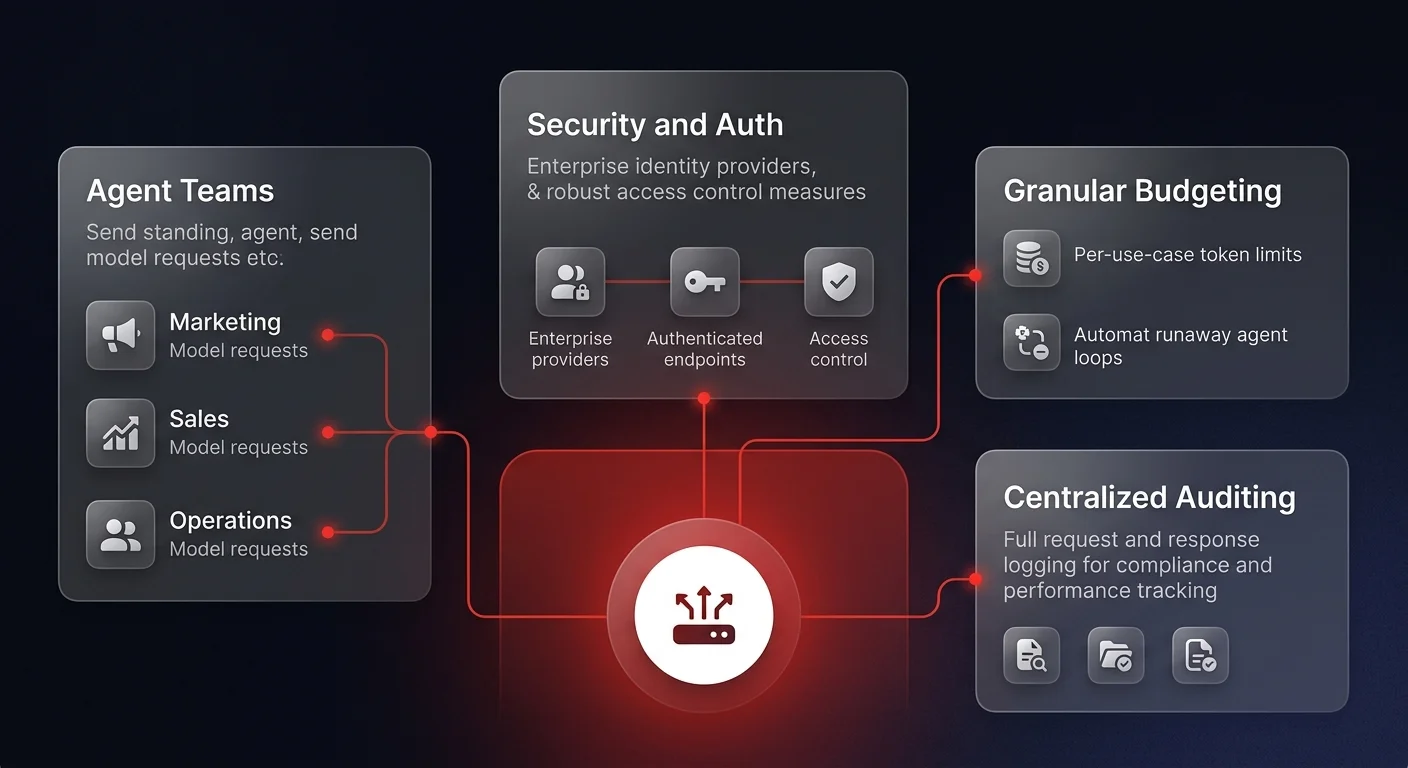
A properly configured AI gateway handles security and authentication (forcing all model requests through enterprise identity providers such as Entra ID), granular budgeting (assigning strict financial limits to specific use cases to prevent runaway costs from infinite agent loops), and centralized auditing (logging every request and response to monitor performance, ensure compliance, and track exact utilization).
By passing all agent traffic through this gateway, the proxy dynamically looks up the registry to route the agent to the correct, authenticated backend server - completely invisibly to the end user. For organizations running autonomous AI agent workflows at scale, this gateway becomes the single most important control point in the entire infrastructure.
Standardizing deployment with developer blueprints
Governance frameworks only succeed if developers actually use them. If enterprise security procedures are too burdensome, teams will inevitably find workarounds, restarting the shadow AI cycle.
To accelerate deployment while maintaining strict compliance, operations teams should provide standardized, production-ready developer blueprints. These are template repositories that contain pre-configured boilerplate code for building MCP servers and A2A agents.
These blueprints come with critical infrastructure baked in: pre-configured Docker files and package managers, standardized API architectures, automated cost-tracking and authentication headers, and built-in observability integrations to trace agent execution and evaluate performance.
Importantly, these blueprints should remain framework-agnostic. Whether an engineering team prefers to build with LangChain, Agno, or custom Python, they can use their framework of choice - provided they conform to the standardized interfaces and ports required by the enterprise blueprint.
When development is finished, standardized CI/CD pipelines automatically push the Docker images to the artifact repository and publish the metadata directly into the centralized registries. This makes doing the right thing the easiest thing for developers - addressing the root cause of shadow AI at the source.
Moving from chaos to governed AI ecosystems
The transition from fragmented AI experiments to reliable, operational systems requires a fundamental shift in how leadership views artificial intelligence. AI can no longer be treated as a collection of independent software subscriptions; it must be managed as core enterprise infrastructure.
The framework demonstrated by global leaders - a unified gateway paired with interconnected MCP, A2A, and Use Case registries - provides the exact observability and control required to scale AI agent governance safely. It ensures that business logic remains transparent, costs remain predictable, and system maintenance is proactive rather than reactive.
Organizations that build this foundation turn isolated technical experiments into reliable, observable engines for business growth. If you are ready to move from shadow AI chaos to a governed AI infrastructure, explore how Trinity, our deep agent orchestration platform, provides the centralized gateway, observable logic, and multi-agent coordination layer that enterprise governance frameworks require — or read our guide to AI workflow automation governance for the next layer of operational controls.