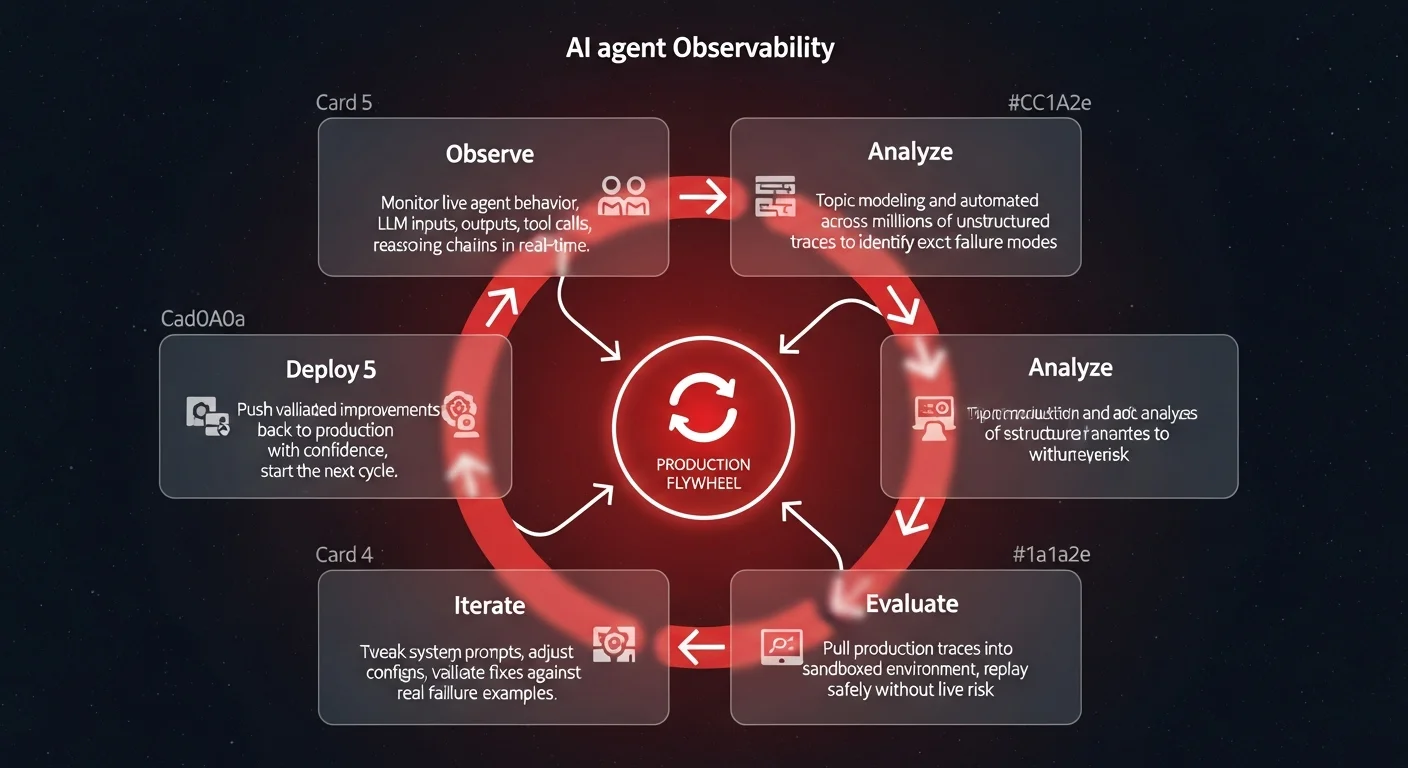
AI agent observability is the monitoring, evaluation, and governance of autonomous AI agents across their full production lifecycle. Without it, organizations face a predictable trap: agents deliver impressive demos but collapse in production, generating compliance risks, runaway infrastructure costs, and brand damage with zero visibility into the root cause.
Mastering AI agent observability is no longer an optional luxury for scaling enterprises - it is the critical dividing line between successful artificial intelligence initiatives and failed experiments. Across the industry, organizations are trapped in a frustrating cycle. They successfully generate impressive generative AI proofs of concept, only to watch those initiatives completely stall before reaching production.
The core of this failure lies in the extreme variability of Large Language Models (LLMs). The exact characteristic that makes LLMs so powerful - their ability to reason through a wide variety of unscripted problems - is also their greatest liability. When companies attempt to deploy autonomous AI agents to interact directly with customers or manage core operational workflows, they realize they lack the systems to monitor, evaluate, and govern these agents effectively.
Our research into the engineering realities of AI deployment reveals a harsh truth. Operations leaders and engineering teams routinely underestimate the sheer complexity of evaluating AI quality. They embark on building internal evaluation platforms, only to find themselves bogged down managing a massive, unstructured data infrastructure instead of delivering business value.
The illusion of simplicity in AI agent observability
When organizations first recognize the need to monitor their AI agents, the problem seems deceptively simple. Most engineering teams assume they just need a way to loop through an agent with a few different inputs, compare the outputs, and attach some handwritten notes or scores.
This superficial view leads teams to believe they can simply build a custom internal tool over a weekend. However, measuring agent quality is fundamentally a multi-persona systems problem, not a simple user interface project. Building agents cannot be done by software engineers in isolation. It requires product engineers, systems engineers, and most importantly, Subject Matter Experts (SMEs) who possess domain knowledge but lack technical coding skills.
Without rigorous evaluation frameworks, deploying an AI agent exposes an organization to immense risk. These liabilities span from brand damage caused by rogue conversational agents, to serious compliance violations, to runaway infrastructure costs. To mitigate these risks, organizations must be confident in how an agent will perform under the stress of real-world usage.
The three stages of the AI evaluation maturity trap
Companies typically fall into a predictable and painful maturity curve when attempting to build their own AI observability and evaluation platforms. Understanding this trajectory is critical for operations leaders who want to avoid wasting hundreds of engineering hours.
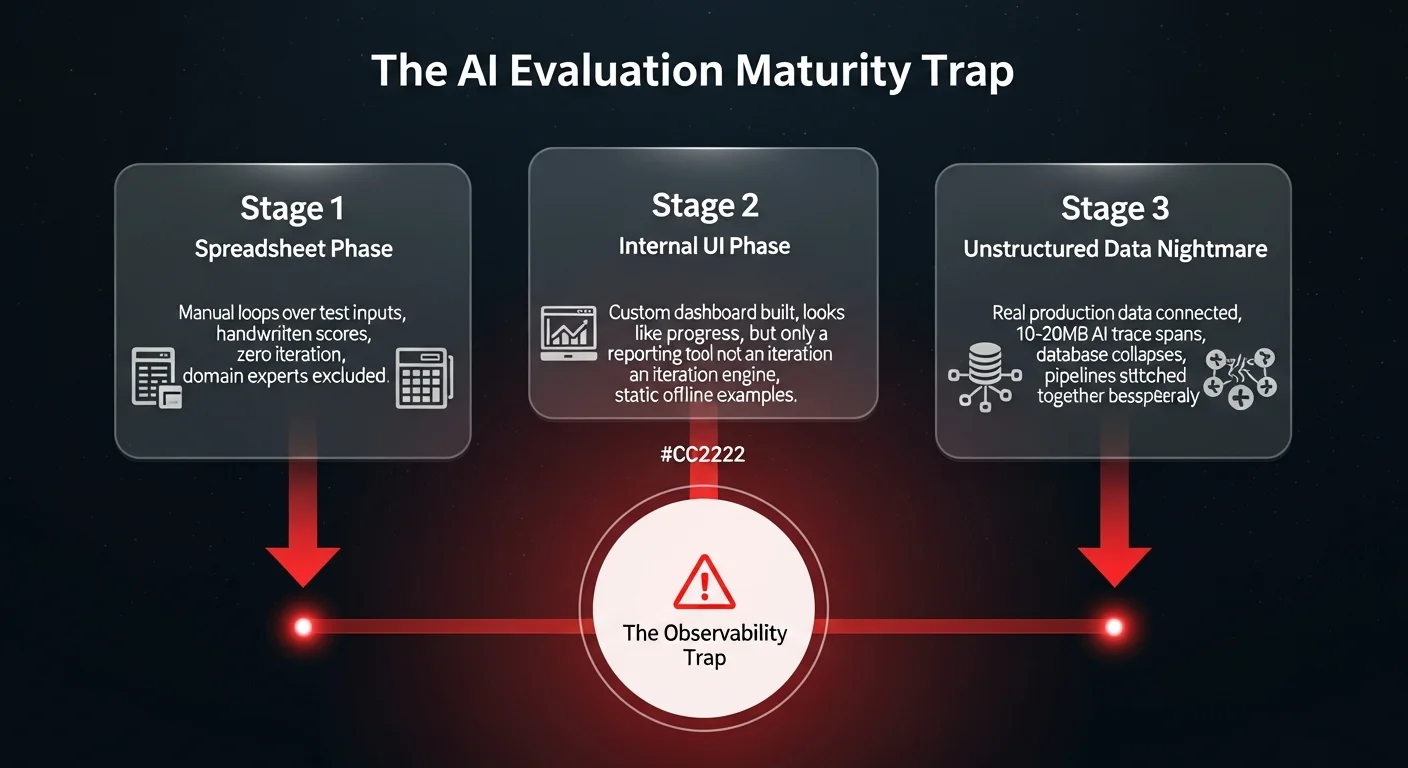
Stage one: the spreadsheet documenting phase
The vast majority of organizations begin their evaluation journey in a spreadsheet. They create a loop to execute their agent against a list of input examples and manually record how the outputs change as they tweak system prompts or underlying logic.
While this is a zero-barrier entry point, the returns diminish almost immediately. This process is not true experimentation - it is mere documentation. It becomes incredibly cumbersome to manage, making it virtually impossible to compare historical experiments directly or scale human scoring efforts. Furthermore, domain experts are unlikely to adopt a clunky spreadsheet workflow, isolating the testing process entirely within the technical team.
Stage two: the vibe-coded internal UI
Recognizing the limitations of spreadsheets, product engineers frequently decide to build a custom user interface. They spin up a database, create a clean dashboard, and proudly present an approachable internal tool.
While this looks like progress and makes the process slightly more collaborative, it is often a decoy. The team has built a reporting tool, not a true iteration engine. They are still relying on static, offline examples rather than observing how the agent behaves dynamically in the wild.
Stage three: the unstructured data nightmare
The real crisis begins when the organization attempts to connect real production data to their evaluation environment. To truly understand failure modes, teams need to observe real usage, analyze those interactions, and pull those examples back into a secure environment to improve the agent.
Suddenly, the scope of the internal tool violently expands. The custom evaluation UI must now transform into a high-velocity logging and tracing data platform. This is where internal builds collapse under their own weight.
This three-stage trap is a primary driver of the ungoverned AI agents and technical debt crisis affecting mid-market companies - where well-intentioned internal tooling investments metastasize into unmaintainable infrastructure that blocks all future AI deployment.
Why agent traces break traditional infrastructure
The fundamental reason internal AI agent observability builds fail is that AI agent traces are entirely different from traditional application traces. In a standard software application, an operational span might be a few kilobytes of structured data. In the world of AI agents, traces are gargantuan, semi-structured, and highly verbose.
Industry data shows that individual AI spans can easily reach 10 to 20 megabytes in size due to the massive context windows and unstructured text inherent to LLM reasoning. When an organization has a successful agent interacting with real users, the data comes in at incredibly high velocity.
Attempting to force a 1-gigabyte text-heavy trace into a standard Postgres database row inevitably leads to catastrophic performance degradation. Organizations often find themselves scrambling to patch together complex data pipelines - trying to stitch together open-source data warehouses, domain-specific query languages, and browser-based data processing tools just to make the dashboard load.
Furthermore, the query patterns for AI observability are unique. Users need instantaneous, low-latency access to view a specific trace to debug an immediate issue. Simultaneously, they require the ability to perform complex, full-text searches across millions of unstructured traces to run aggregate analytics. Traditional relational databases and data warehouses are fundamentally unequipped to handle both of these read patterns efficiently at scale.