GPT-5.5 token efficiency is the ability of GPT-5.5 to execute complex, multi-step AI agent reasoning tasks using 56% fewer tokens than previous flagship models. This breakthrough directly cuts AI compute costs in half for autonomous agent workflows, making sovereign, custom AI systems economically viable for mid-market operations at scale.
Organizations are rapidly realizing that scaling artificial intelligence is as much an economic challenge as it is a technical one. For operations leaders managing high-volume tasks in sales, marketing, and customer support, unpredictable compute costs can quickly erode the ROI of automation. However, recent breakthroughs in model architecture are fundamentally shifting this reality. Our latest research into GPT-5.5 token efficiency reveals a transformative leap in how autonomous systems process complex tasks. By dramatically reducing the computational overhead required for reasoning, this new generation of models is making bespoke, sovereign AI solutions more accessible and cost-effective than ever before.
The compute bottleneck in modern AI operations
Scaling AI across an enterprise typically forces leadership into a difficult corner. When deploying intelligent agents for volume-heavy operations - such as deep lead enrichment, multi-step customer support triage, or complex HR resume screening - the amount of data processed scales exponentially. Historically, complex reasoning tasks meant massive, unpredictable token consumption.
This compute bottleneck is the primary reason many mid-market leaders hesitate to move beyond basic chatbots. The fear of runaway API costs drives organizations toward two equally problematic extremes. They either lock themselves into rigid, off-the-shelf SaaS products that charge exorbitant per-seat platform fees, or they allow ungoverned Shadow AI sprawl to take root, where employees paste sensitive company data into consumer-grade web interfaces. For a detailed breakdown of how this Shadow AI problem compounds over time, see our analysis of the shadow AI governance crisis.
Neither option provides the governance, data sovereignty, or cost control required for serious operational transformation. To truly automate complex workflows, the underlying reasoning engines must become fundamentally more efficient. For operations leaders ready to explore custom solutions without vendor dependencies, the operations automation solutions hub outlines proven approaches to building AI infrastructure your team fully controls.
How GPT-5.5 token efficiency changes the math
Recent performance data from agent workflow optimizations leveraging GPT-5.5 demonstrates a complete paradigm shift in operational economics. When agent workflows are deliberately optimized for compute alongside this highly precise model, the efficiency gains are staggering.
Our research indicates that GPT-5.5 can perform the exact same complicated, multi-step reasoning tasks using 56% fewer tokens than previous flagship models.
This 56% reduction is not merely a technical footnote - it is a strategic advantage for scaling companies. If an autonomous sales agent previously required heavy token expenditure to research a prospect, analyze their recent company news, and draft a hyper-personalized outreach sequence, that identical workflow now operates at less than half the compute cost.

For organizations running thousands of these operations daily, this efficiency instantly transforms the financial viability of custom AI. It proves that well-architected Sovereign AI Agent Systems are highly economical for volume-heavy tasks, eliminating the unpredictable cost barriers that have historically kept mid-market companies from adopting custom AI solutions. Our analysis of AI agent framework ROI breaks down how to measure these cost savings across different deployment scenarios.
Accelerating internal tool development
Beyond execution efficiency, the precision of GPT-5.5 is fundamentally accelerating how fast custom operational engines can be built. In the past, developing a specialized internal tool required weeks of engineering, testing, and debugging to account for model hallucinations and workflow breakdowns.
However, the integration of highly precise models with coding assistants like Codex is compressing development timelines dramatically. According to our observations, internal tools that were previously deferred because they were projected to take several days to build are now being completed in under one hour.
This hyper-accelerated development cycle is the exact mechanism that enables a Solution-First model. The days of signing massive, slow consulting contracts that take months to show value are over. By leveraging the precision of GPT-5.5, organizations can scope a focused Starter Project - designed to solve a specific operational pain point - and deploy it in weeks, not months, for a fixed cost.
Faster execution and improved user feedback loops
GPT-5.5 token efficiency does more than just protect the bottom line - it fundamentally improves the performance latency of agentic systems. In the context of large language models, lower token consumption directly translates to faster processing speeds.
When workflows consume 56% fewer tokens to reach a conclusion, the time-to-output drops significantly. This speed is critical when human-in-the-loop workflows are involved. For a customer success representative waiting on an AI agent to summarize a complex ticket history and recommend a resolution path, a delay of fifteen seconds disrupts their operational flow.
By delivering faster execution, GPT-5.5 ensures tighter, more responsive feedback loops with end users. Agents can operate seamlessly alongside human teams without introducing frustrating bottlenecks, driving higher internal adoption rates and keeping operational cadences fluid.
Moving from SaaS sprawl to sovereign AI systems
The dual advantages of a 56% drop in token usage and radically compressed development times reinforce a crucial strategic shift for business leaders. You no longer need to pay recurring platform fees for generic SaaS wrappers that offer limited customization.
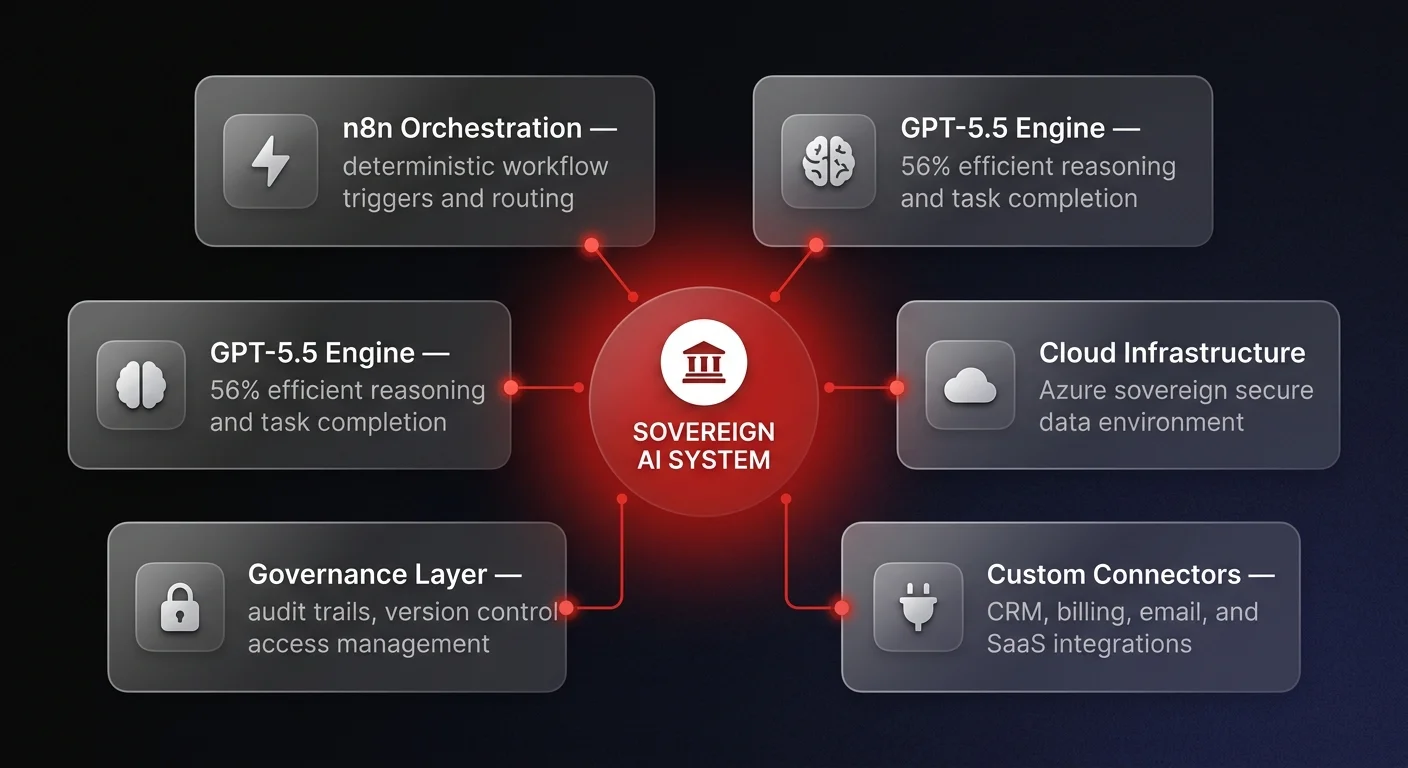
The barrier to entry for owning your own custom AI infrastructure has vanished. With robust orchestration platforms like n8n for battle-tested workflow automation, cognitive engines utilizing GPT-5.5, and platforms like Microsoft Azure to meet strict security requirements, organizations can build powerful internal systems that they fully control. If you are currently locked into vendor platforms with escalating seat fees, our guide on AI vendor lock-in risks outlines exactly what the transition to sovereign infrastructure looks like.
This Land and Expand approach allows you to start small. You can prove immediate value with a tightly scoped automated workflow, validate the reduced compute costs, and establish secure data governance before expanding into a long-term transformation partnership.
The operational imperative for efficient AI
The key takeaway - the economics of autonomous operations have permanently shifted in favor of the enterprise. GPT-5.5 has proven that deep, complex reasoning no longer requires a prohibitive compute budget. With token usage slashed by 56% and development timelines shrinking from days to hours, the excuse that custom AI is too expensive or too slow to build is no longer valid.
Operations leaders must stop treating AI as a series of fragmented SaaS subscriptions and begin treating it as core, sovereign infrastructure. By focusing on highly efficient, centrally governed AI agent systems, you can eliminate Shadow AI risks, dramatically reduce operational costs, and finally achieve the scalable growth that modern automation promises. The tools are ready, the costs are optimized, and the path forward requires owning your solutions, not renting them.