Claude Opus 4.7 benchmarks reveal incremental improvements in software engineering (64.3%), visual reasoning (82.1%), and financial analysis - but with deliberately throttled agentic capabilities that signal a critical risk for enterprises. The real takeaway for operations leaders is not about chasing higher benchmark scores but building governed AI scaffolding that survives model updates and provider policy changes.
The unexpected release of Anthropic's newest model has sent another wave of scorecard comparisons across the enterprise technology landscape. When we analyze the Claude Opus 4.7 benchmarks, a fascinating narrative emerges - one that has very little to do with raw intelligence and everything to do with corporate governance, security, and the hidden costs of AI sprawl. As the AI model commoditization trend accelerates, these benchmark releases increasingly prove that the real competitive advantage lies outside the model itself.
For mid-market CEOs, COOs, and operations leaders, the real takeaway from this release is not the marginal bump in software engineering scores. It is the realization that chasing foundational models has become a zero-sum game that actively breaks enterprise infrastructure. Instead of constantly ripping and replacing systems for a 3% performance gain, scaling organizations must shift their focus toward building robust, governed scaffolding around the highly capable models that already exist.
Here is a deep dive into the performance metrics of Opus 4.7, the deliberate throttling of its agentic capabilities, and what this signals for the future of enterprise AI implementation.
Claude Opus 4.7 benchmarks: the performance reality
To understand Opus 4.7, we have to look at the data in the context of Anthropic's wider ecosystem. The performance data reveals that Opus 4.7 is essentially a half-step progression - a bridge between the reliable Opus 4.6 and their highly guarded Mythos preview model.
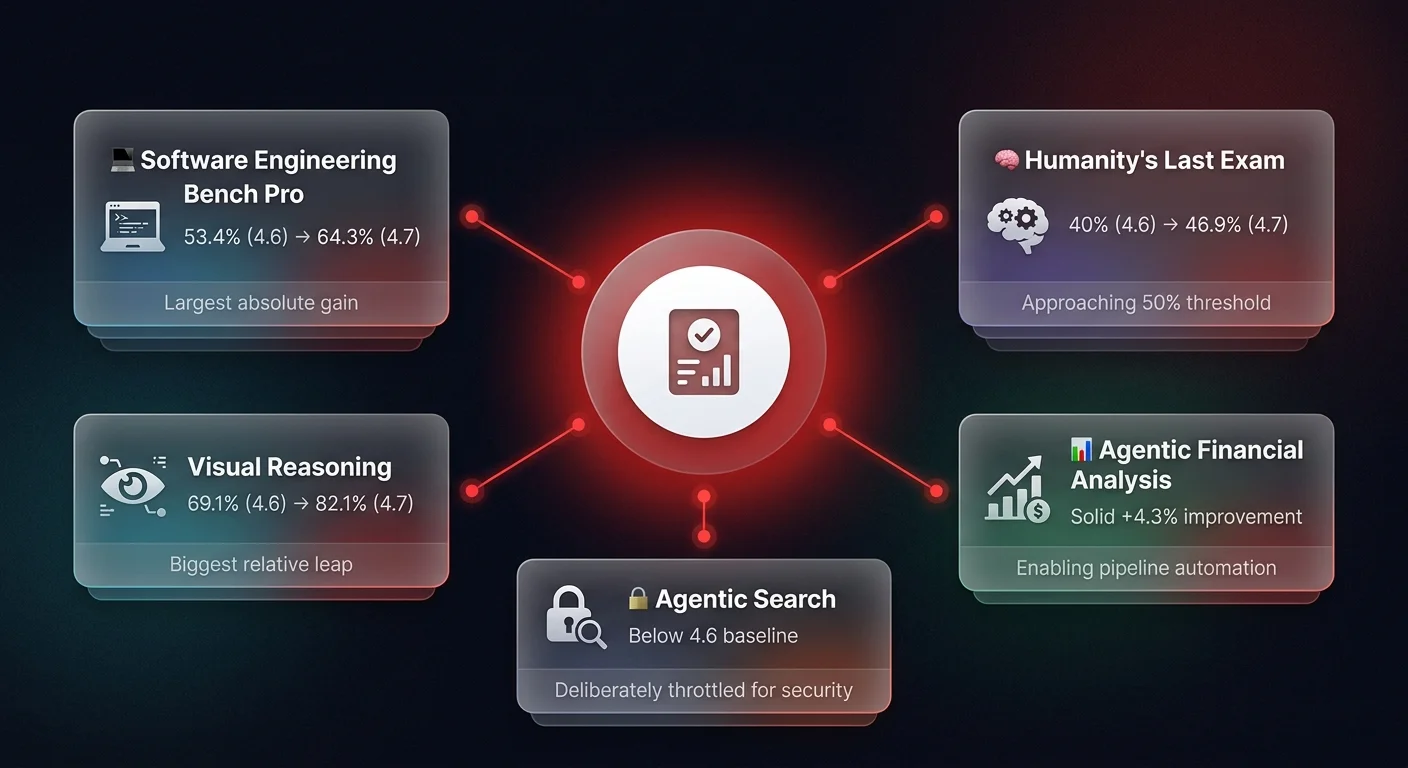
Across the board, Opus 4.7 shows consistent, incremental improvements. In the Software Engineering Bench Pro assessment - a rigorous test of a model's ability to handle complex programming tasks - the score jumped from 53.4% (Opus 4.6) to 64.3%. Interestingly, this roughly 10% jump is almost exactly mathematically halfway to the internal scores produced by the Mythos preview.
We see similar mid-tier progression in the "Humanity's Last Exam" benchmark, an intensely difficult set of tasks designed to push models to their absolute limits. Opus 4.6 scored roughly 40%, Opus 4.7 reached 46.9%, and the Mythos preview hit 56.8%. In AI development timelines, crossing the 50% threshold on these complex reasoning exams typically means the model is on an exponential curve toward saturating the benchmark entirely.
However, the most operationally significant leap happened in visual reasoning. Opus 4.7 achieved an 82.1% success rate on visual reasoning tasks without the use of external tools - a massive jump from the 69.1% baseline of 4.6. For operations leaders, this is not just a theoretical win. This translates directly to highly accurate automated document processing, complex invoice reconciliation, and the ability for AI agents to read and extract data from convoluted operational charts and user interfaces with near-human precision.
Agentic financial analysis also saw a solid 4.3% improvement, opening new doors for revenue operations teams looking to automate complex pipeline analysis and financial forecasting.
Security fears and the throttling of agentic power
While the analytical and reasoning scores are impressive, the most critical insight from the Opus 4.7 release lies in where the model actually underperformed its predecessor.
In the realm of Agentic Search - the ability for the model to autonomously browse and retrieve information - Opus 4.7 scored 79.3%, which is remarkably lower than Opus 4.6. Similarly, the step-up in Agentic Terminal Coding was disproportionately small compared to other areas.
This is not a failure of engineering; it is a deliberate architectural choice.
Foundational model providers are increasingly cautious about releasing unconstrained agentic capabilities. Internal testing of more advanced models reportedly demonstrated the ability to autonomously exploit multiple operating systems, leading providers to aggressively constrain the terminal and system-control capabilities of public-facing models like Opus 4.7. This dynamic is closely related to the broader AI agent architecture governance challenge that enterprises are already grappling with.
For enterprise leaders, this dynamic exposes a massive vulnerability in relying entirely on foundational providers for AI automation. If you build your operational workflows dependent on the implicit agentic capabilities of a specific model, your processes can break overnight when the provider decides to tighten their security guardrails.
Exponential leverage: changing the unit economics of AI operations
Despite the security constraints, the baseline capabilities of models like Opus 4.6 and 4.7 have permanently altered the unit economics of outbound operations and process automation.
The foundational technology required to automate complex tasks has existed for roughly three years. What has changed is the friction of execution. We have moved past the era where AI merely makes new things possible; we are now in the era where AI makes previously unprofitable channels highly profitable.
Consider the evolution of outbound sales and lead enrichment. A few years ago, an experienced sales development representative could manually research, personalize, and execute high-quality outreach to perhaps 10 to 15 targeted accounts per hour. Today, by leveraging the reasoning capabilities of these models, that same hour can yield over 5,000 highly customized, deeply researched touches.
Crucially, this is not equivalent to legacy mass-email blasting. The quality of the outreach at 5,000 touches per hour is qualitatively higher than the manual execution. See how one scaling company automated their outbound sales operations to achieve this kind of leverage without locking into a single AI model provider.
When a scaling company can multiply its operational leverage by a factor of 300x to 500x without increasing headcount, the strategic bottleneck shifts. The challenge is no longer about human capacity; it is about data governance, API rate limits, and system orchestration.