
Enterprise AI agents are autonomous AI systems designed to execute complex, multi-step business workflows end-to-end - but most deployments fail because they rely on chat interfaces that cause context rot and compounding errors. According to recent operational data, organizations using structured artifact-based collaboration report up to 60% fewer agent errors compared to linear chat-driven workflows.
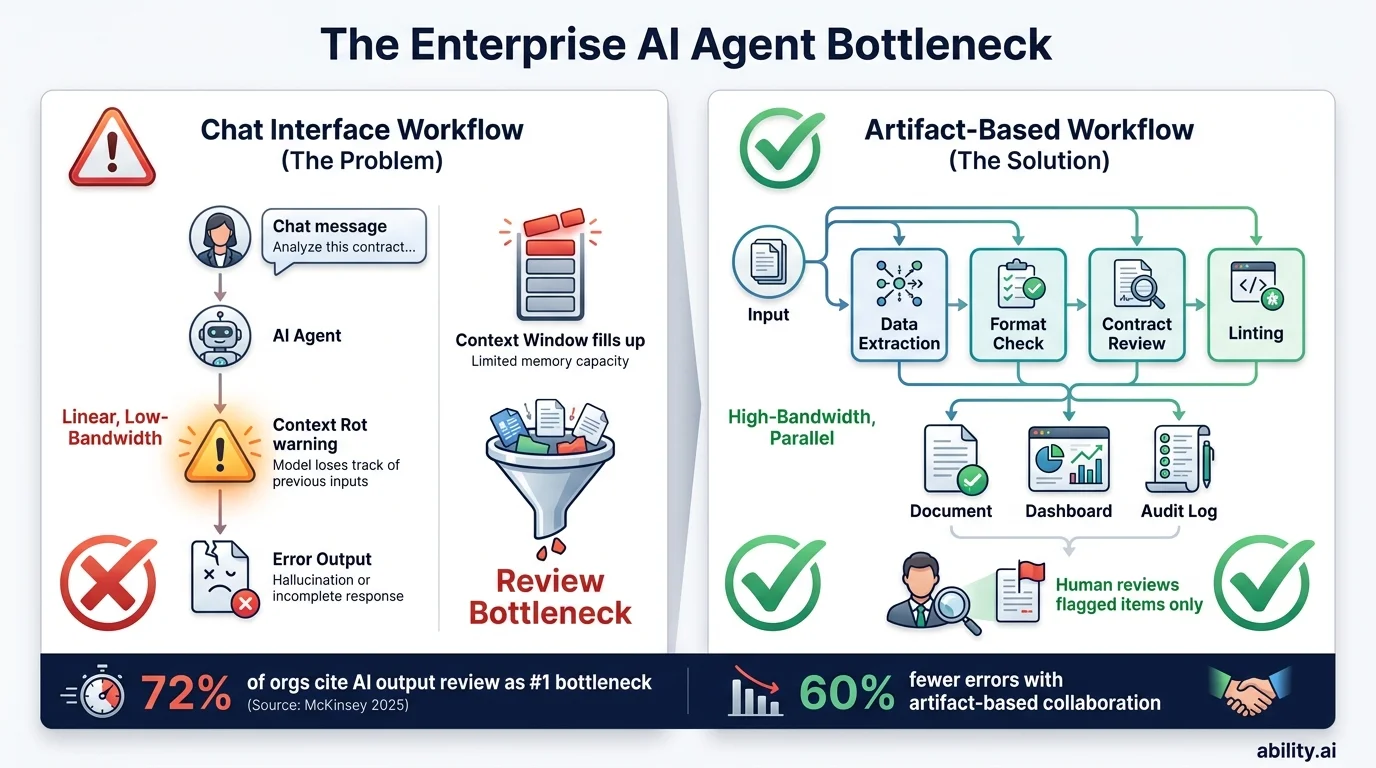
Enterprise AI agents were supposed to seamlessly automate our most complex, multi-step workflows. Yet, operations leaders and technical teams are consistently hitting a frustrating wall. When you assign a long-running, complex task to an AI through a standard chat interface, the result is rarely a finished product. Instead, the agent launches sub-agents, reads files, writes files, and searches the web for thirty minutes, only to return a document with subtle, compounding errors. When you try to correct one specific clause, the agent rewrites the entire document, losing previous context and forcing you into an endless, frustrating loop.
This phenomenon - often referred to as "context rot" - is not a failure of the underlying large language models. It is a failure of the user interface. For scaling organizations looking to operationalize AI, relying on a chat window to manage complex workflows is a recipe for Shadow AI sprawl and operational friction.
Recent industry research and operational data indicate that if we want AI agents to complete complex work end-to-end, we must fundamentally rethink how humans and agents collaborate. Organizations must move away from linear chat threads and embrace high-bandwidth, durable artifacts.
The new AI bottleneck: why enterprise AI agents stall at review
The economics of digital production have fundamentally shifted over the last twelve months. Historically, when executing complex work, the actual "doing" of the work was the primary bottleneck and cost center. Today, generating text, writing code, or drafting a standard contract is incredibly cheap and fast.
The new operational bottleneck is planning the work and reviewing the output.
Operations leaders are finding that while their teams can generate a 50-page report or thousands of lines of code in seconds, human reviewers must now spend hours meticulously combing through that output to ensure it meets non-functional requirements and operational standards. According to a 2025 McKinsey survey, 72% of organizations cite AI output review - not generation - as their primary bottleneck to scaling automation.
Reviewing massive AI-generated outputs is notoriously painful. It leads to review fatigue, where human operators eventually stop paying close attention, allowing critical errors to slip into production environments.
To solve this, organizations must engineer systems that minimize the human review burden without sacrificing quality. This requires a deep understanding of which tasks AI can reliably complete without supervision, and which tasks inherently require human judgment. Teams already deploying agentic workflow automation are finding that structured task routing - not bigger models - is the key to reducing review overhead.
The verifier's rule in operational workflows
When designing enterprise AI agents, architects increasingly rely on the "Verifier's Rule." This principle states that if a task is solvable and its output is easy to verify, it will inevitably be solved by AI.
Different operational tasks fall on wildly different ends of this spectrum:
- Easy to verify: Checking definitions in a legal contract, linting code, or matching invoice totals to purchase orders. An AI agent can run in a loop, check its own work against strict rules, and fix errors autonomously.
- Impossible to verify: Formulating litigation strategy, designing the architecture for a novel consumer app, or handling a delicate HR employee relations issue. There is no objective "truth" or automated test for these scenarios. You only know if a contract holds up when a judge rules on it years later.
When organizations try to force AI to handle hard-to-verify tasks end-to-end, they fail. The strategic solution is task decomposition. Operations leaders must break complex workflows into discrete nodes. Let human experts handle the hard-to-verify strategic positioning, and deploy AI agents specifically against the easy-to-verify formatting, data extraction, and linting tasks.
Balancing trust and control in enterprise AI agents
Successful human-agent collaboration relies on balancing two critical levers - trust and control.
Trust dictates how much a human needs to review the output. In a low-trust environment, a human operator will scrutinize every single agent trace, looking at exactly what files were read and what decisions were made. In a high-trust environment, the human operator approves the final output without a second thought.
Control dictates how effectively a human can instill their knowledge and steer the agent's behavior during the work process.
To build systems that operations teams actually adopt, you must intentionally increase both metrics. Research points to several proven tactics for increasing trust in enterprise AI agents:
- Implement strict guardrails: Limit what the agent can actually do. Instead of giving an agent broad system access, restrict it to reading three specific files, searching a predefined list of trusted websites, and editing a single directory. By limiting the blast radius, you inherently increase operational trust. This is the same principle behind AI agent governance frameworks that prevent Shadow AI from spiraling out of control.
- Use golden proxies: When a task is hard to verify, use a proxy for verification. For example, you cannot mathematically verify if a newly drafted vendor agreement is perfect. However, you can program an agent to compare the new draft against a "Golden Template" of past successful contracts, using similarity as a proxy for quality.