
Multi-agent AI orchestration is the architectural practice of coordinating multiple specialized AI agents through a central controller that governs execution order, state management, and failure recovery across complex business workflows. According to recent enterprise deployment data, organizations moving from single-agent to multi-agent systems see complexity grow quadratically - making governed orchestration the difference between operational success and system collapse.
The transition from a single AI assistant to a comprehensive automated workforce is where most enterprise initiatives silently derail. A single agent works beautifully in isolation. It demos perfectly, leadership signs off, and operations teams prepare for massive efficiency gains. But when you move to connect multiple specialized agents to handle a complete business process, the architecture fundamentally changes. Multi-agent AI orchestration is the only way to prevent this operational transition from resulting in complete system collapse.
The reality that most organizations discover too late is that adding more agents is not like adding more features to a software application. It is the creation of a highly complex distributed system. Without a governed, observable infrastructure, these interconnected agents rapidly generate operational chaos, data corruption, and catastrophic process failures - a pattern explored in depth in our analysis of multi-agent AI architecture design principles.
This research examines the critical architectural patterns required to transform fragile multi-agent experiments into resilient, governed operational systems.
The distributed systems illusion: why multi-agent AI orchestration complexity explodes
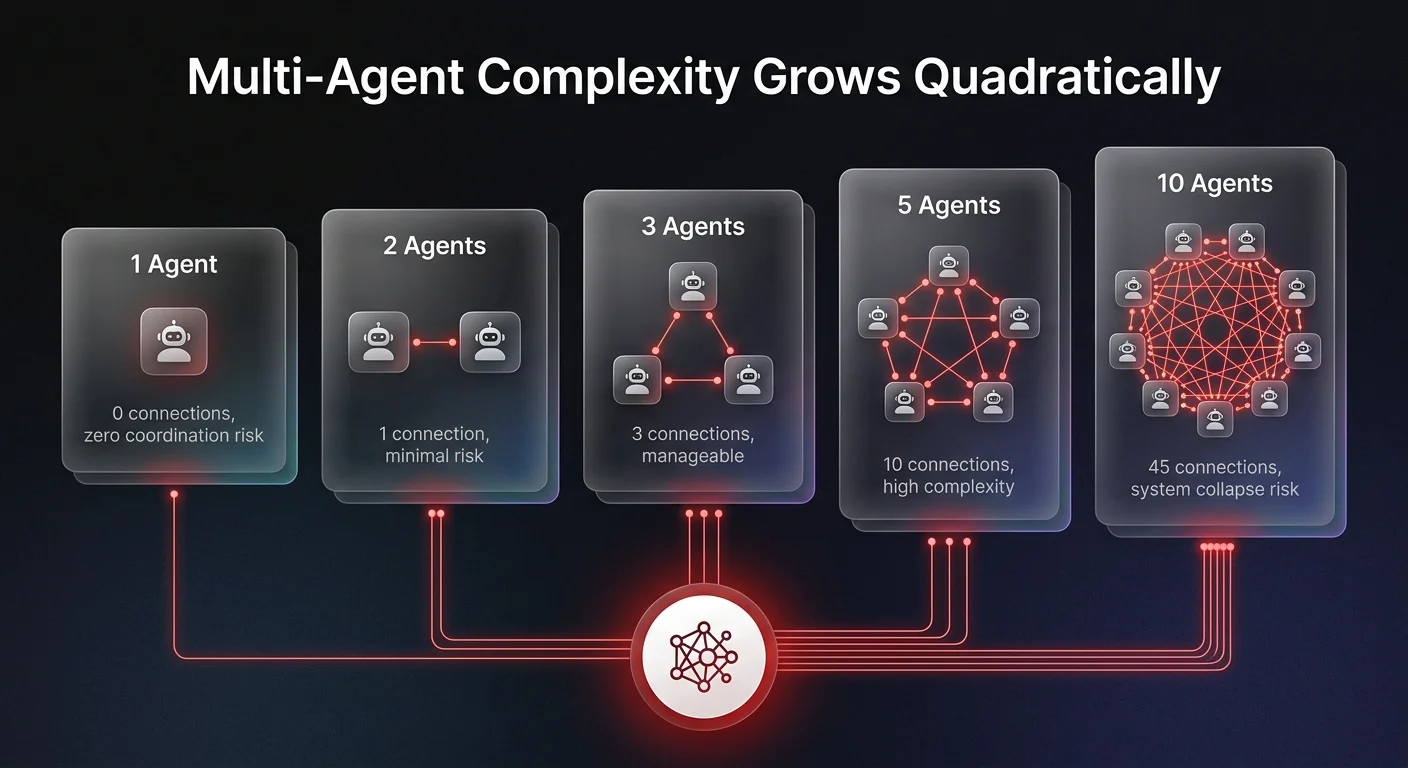
When operations leaders approve the expansion from a single-agent system to a five-agent workflow, the assumption is that complexity scales linearly. The reality is far more volatile. Moving from one agent to five does not make the system five times harder to manage - it makes it twenty-five times more complex.
A single agent operates with zero coordination problems. Two agents share at least one connection. Five agents introduce at least ten potential connections, overlapping workflows, and coordination handoffs. Every single connection between these agents represents a potential failure point, a race condition, or a state synchronization error.
Consider a recent production case study in the financial services sector. An operations team deployed a credit decisioning system starting with a single agent designed to calculate credit scores. For two weeks in production, it operated with zero issues. Encouraged by this success, the team rapidly deployed four additional agents to handle income verification, risk assessment, fraud detection, and final approval.
Within three days, twenty percent of the automated decisions had incorrect risk ratings. Customers who should have been flagged for fraud were being automatically approved.
The root cause was not a hallucinating AI model or poorly written prompts. It was a classic distributed systems failure. The credit score agent calculated a score of 750 and successfully wrote it to the database. However, the architecture included a caching layer for customer records. The risk assessment agent read from that cache 500 milliseconds later. Because the cache had not been invalidated in time, the risk agent received stale data - a previous score of 680 - and executed the wrong business logic.
The failure was a race condition born from bad architecture. The agents shared a cache with no central coordination for invalidation. This is the danger of deploying ungoverned AI tools into operational environments - bad architecture will cause systemic business damage long before the AI model itself makes a mistake. Organizations exploring agentic workflow automation must understand these coordination risks before scaling.
Choosing your coordination pattern: choreography vs orchestration
To prevent interconnected agents from corrupting business processes, organizations must explicitly define how these agents coordinate. There are two fundamental patterns for distributed coordination - choreography and orchestration.
The limits of choreography
Choreography is entirely decentralized and event-driven. In this pattern, agents operate autonomously. A research agent might finish its task and publish a "research completed" event to a shared message bus. An analysis agent, subscribed to that specific event type, picks it up, performs its task, and publishes an "analysis ready" event.
There is no central coordinator dictating the workflow. Each agent simply listens for the events it cares about and acts independently. This loosely coupled approach allows engineering teams to add new agents easily, driving high autonomy.
However, in an enterprise operational environment, choreography frequently becomes a debugging nightmare. When a critical business process fails, operations teams are left playing detective. Did the first agent fail to publish the event? Did the second agent consume the event twice? Without bulletproof observability and tracing, identifying the point of failure is nearly impossible. Teams that choose choreography because it feels more "agentic" often spend months firefighting opaque, untraceable event flows.
The necessity of orchestration
Orchestration, conversely, relies on a central coordinator to manage the entire workflow. In an orchestrated system, agents never communicate with each other directly.
The orchestrator calls the first agent, waits for the result, and receives the output. It then calls the next agents - potentially managing parallel execution - and routes the combined results forward. The orchestrator serves as the single source of truth. It manages the state, handles execution retries, logs every step, and dictates the entire execution graph.
For mid-market and scaling operations, orchestration is almost exclusively the correct choice. When managing complex workflows with low tolerance for error - such as financial approvals, customer support resolutions, or compliance checks - you require total observability. If an automated process makes an incorrect decision, operations leaders need a centralized dashboard showing exactly which agent was called, in what order, and with what data. Orchestration guarantees this level of governance. This is why operations automation strategies increasingly rely on centralized orchestration as their foundation.
Solving the state management crisis with immutable data
The most common way multi-agent systems break at scale involves state management - specifically, how agents share data without causing race conditions or stale reads.
The standard, flawed approach is utilizing shared mutable state. This occurs when multiple agents are allowed to write to and update the same database records simultaneously. If Agent A and Agent B both read a value of 680, and Agent A updates it to 750 while Agent B updates it to 720 a millisecond later, Agent A's update is entirely lost. According to distributed systems research, race conditions in multi-agent deployments account for an estimated 30-40% of production failures in automated decision systems. While modern databases have protections like row locks and isolation levels, they are rarely implemented correctly in rapid AI deployments, resulting in data corruption.
The enterprise-grade solution relies on immutable state snapshots with strict versioning.
Under this architecture, when an agent completes its work, it produces a state version - for example, Version 1. This state is sealed and immutable; it cannot be modified by any other agent. The data is stored in the orchestrator's database as an append-only log.
When the next agent receives the data, it must first validate the schema to ensure the data contract is met. Once processed, it does not update Version 1. Instead, it generates a completely new, immutable record - Version 2.
If the system crashes at Version 7, the operations team can seamlessly replay the state evolution through Versions 1 through 6. They can see exactly what data was passed at every single handoff. This eliminates race conditions entirely, ensures a clear audit lineage, and enforces strict data sovereignty throughout the automated workflow. For organizations building sovereign AI agents infrastructure, immutable state is a non-negotiable architectural requirement.
