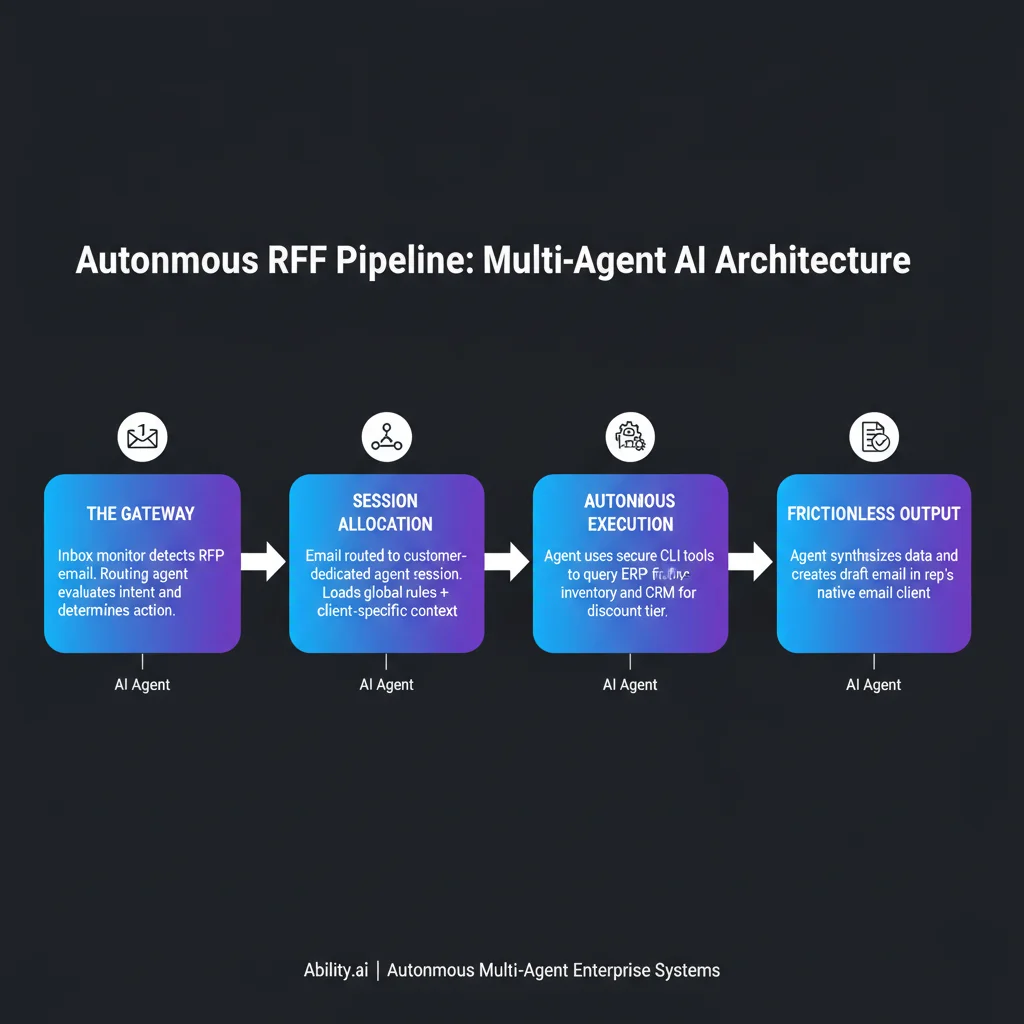
Multi-agent AI architecture is a system design pattern where multiple specialized AI agents collaborate through orchestration infrastructure to autonomously execute complex business processes. Unlike single coding assistants, multi-agent AI systems use persistent shared state, context segregation, and sandboxed tool execution to handle enterprise workflows end-to-end - from RFP processing to CRM automation.
The transition from experimental desktop assistants to enterprise-grade multi-agent AI architecture represents the most critical engineering shift facing technical leaders today. We are currently emerging from what industry researchers accurately describe as the experimental phase of coding agents. Organizations are realizing that the true value of these systems does not lie in helping individual developers write isolated scripts. Instead, the future belongs to embedded, multi-agent business systems that autonomously orchestrate core operations.
For CTOs and internal AI champions at scaling companies, the challenge is no longer figuring out how to prompt an LLM. The challenge is architectural - how do you transition from single-player, stateless chat interfaces to a persistent, governed infrastructure where autonomous agents execute complex business processes?
Recent technical implementations in the open-source community offer a blueprint for this transition. By stripping away the bloated user interfaces of commercial AI tools and examining the core loops of agent frameworks, we can extract critical patterns for building robust, multi-agent AI systems.
Why multi-agent AI architecture outperforms monolithic systems
At its most fundamental level, an AI agent is simply an LLM that runs tools in a continuous loop. It receives a goal, processes context, makes a tool call, evaluates the result, and loops back until the objective is achieved.
When this loop is wrapped in a shell and paired with a runtime environment, you get a coding agent. But when you abstract that same mechanics - the continuous reasoning loop and tool execution - away from the developer's desktop and embed it into your backend systems, you create operational infrastructure.
This shift requires a new way of thinking about AI deployment. Most organizations attempt to build massive, monolithic AI systems that try to understand the entire business context at once. This approach consistently fails, resulting in hallucinations, infinite loops, and broken data integrations. The alternative pattern emerging in successful enterprise deployments relies on a much older architectural concept.
The Unix philosophy for multi-agent AI tool integration
Ken Thompson, the inventor of Unix, famously established the philosophy: write programs that do one thing and do it well. This principle is becoming the golden rule for AI agent architecture.
When building tools for agents to use, engineers often make the mistake of providing massive, complex APIs. However, agents operate most reliably when they are given small, highly focused Command Line Interfaces (CLIs) or micro-tools.
Consider how leading desktop agents interact with complex software like Excel. They do not attempt to learn the entire Microsoft Graph API. Instead, they utilize small, specific packages - like Pandas or OpenPyXL - bundled into a single skill. From the outside, it looks like a complex integration, but internally, the agent is simply executing a basic, well-scoped micro-tool.
For CTOs architecting multi-agent systems, the directive is clear - make it easy for the agents. If you want an autonomous system to update your CRM or query your ERP, do not force the LLM to navigate complex OAuth flows and massive JSON payloads. Build simple, deterministic CLI tools that the agent can trigger with basic arguments. The complexity should live in your infrastructure, not in the agent's prompt. Organizations that have already adopted modular agent architectures consistently report higher reliability and faster iteration cycles.
Context segregation and persistent session memory
Moving beyond single-use chat interfaces requires a sophisticated approach to state and memory. In a multi-agent system, context cannot be a massive, unstructured text dump. It must be cleanly segregated.
Technical implementations of successful autonomous systems utilize strict context boundaries:
- General rules (agent.md): This defines the global behavioral constraints, the system's purpose, and the operational boundaries. It instructs the agent on how to use its available tools and how to handle errors.
- Entity-specific context (customer.md): This provides localized information. In a B2B setting, this might include a specific client's historical quirks, custom discount tiers, or unique SLA requirements.
By separating the "how to operate" from the "who I am operating on," systems can dynamically load context based on the incoming trigger. Furthermore, these systems rely on persistent session management. Instead of starting from scratch with every interaction, the system loads a historical thread, allowing the agent to "remember" previous tool calls and context. This persistent shared state is what elevates a basic script into true company infrastructure. Teams struggling with context degradation in long-running agents find that proper context segregation eliminates most reliability issues.