
Small language models are compact AI models (350M-7B parameters) purpose-built for specialized agentic workflows rather than general-purpose chat. Unlike massive frontier models, they run on-device or in private infrastructure with dramatically lower latency and token costs - making them the emerging backbone of Sovereign AI Agent Systems for mid-market and enterprise operations.
The enterprise AI landscape has been dominated by a singular, expensive assumption: bigger is always better. However, recent research into small language models proves that this conventional wisdom is actively harming operational efficiency. Organizations are caught between two equally damaging options - ungoverned Shadow AI sprawl via massive public chatbots, and bloated, slow-moving consulting projects. But a third path is emerging from the frontier of edge computing.
Small language models - typically ranging from 350 million to a few billion parameters - are proving that massive knowledge capacity is not a prerequisite for complex automation. By focusing on reasoning and tool usage rather than encyclopedic knowledge, these compact models offer mid-market companies a way to deploy highly secure, low-latency Sovereign AI Agent Systems without the exorbitant token costs of general-purpose models.
Why small language models are redefining agentic AI
When evaluating compact models for enterprise operations, the first mistake engineering and leadership teams make is treating them as shrunken versions of massive systems. Small language models possess fundamentally different characteristics: they are inherently memory-bound, latency-sensitive, and highly task-specific.
A deep dive into model architectures reveals why purpose-built edge models outperform simply scaled-down giants. Consider models like Gemma 3 270M and Qwen 3.5 0.8B. While both adopt hybrid architectures to improve speed, a massive percentage of their parameter count is dedicated solely to the embedding layer - 63% for Gemma 3 270M and 29% for Qwen 3.5. This inflation happens because these models are distilled from massive teacher models with enormous vocabulary sizes.
From an operational standpoint, this is highly inefficient. The parameters dedicated to embeddings are not "effective parameters" - they do not contribute to the actual reasoning or logic capabilities of the model.
Conversely, purpose-built edge architectures like LFM2 utilize gated short convolutions, which are significantly faster than sliding window attention or standard group query attention. By optimizing for the actual target hardware, these architectures reduce the embedding layer to roughly 19% of the total parameters. This allows the model to squeeze vastly more reasoning capability and performance out of the exact same memory footprint. On-device profiling across standard CPUs - such as AMD Ryzen processors or even mobile processors like the Samsung Galaxy S25 Ultra - demonstrates that short convolutions allow these models to achieve dramatically higher throughput with lower memory utilization.

The architecture of efficient reasoning
The training lifecycle of these compact models also defies conventional scaling laws. Traditional Chinchilla scaling laws suggest that a 350 million parameter model reaches its compute-optimal state relatively early. However, recent test-time scaling research proves otherwise.
Pre-training a 350 million parameter model on an astonishing 28 trillion tokens yields continuous performance growth. This heavy investment in pre-training at a micro-scale creates models that excel at highly specific tasks. While they may not be the industry's best coding assistants or mathematicians, they become remarkably proficient at critical operational workflows: data extraction, instruction following, and tool utilization. Benchmarks across frameworks like IF-Bench and ToolBench confirm that overwhelming a small parameter space with massive token volume creates a highly capable execution engine.
Overcoming the doom-loop crisis in complex tasks
Deploying small models for reasoning tasks introduces a unique, critical failure mode: the doom-loop. A doom-loop occurs when an AI model gets stuck repeating the same sequence of words infinitely, unable to break the cycle and complete the task.
This failure state happens when three conditions perfectly align - you are using a tiny reasoning model, applied to a highly complex task, that exceeds the model's base comprehension. If you simply scale down a massive model and ask it to perform complex logic, you will experience doom-looping in over 50% of its outputs.
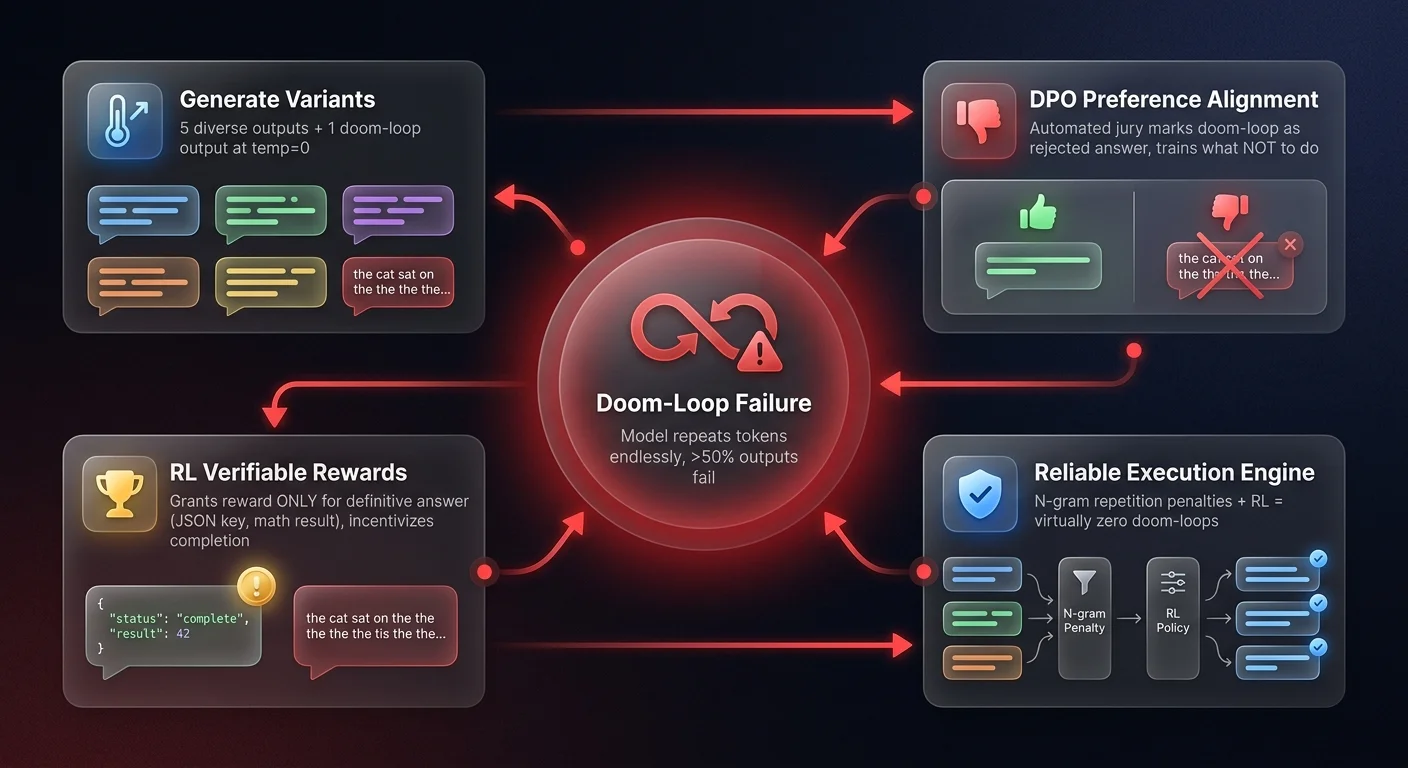
Standard Supervised Fine-Tuning (SFT) does almost nothing to resolve this issue. Instead, the solution lies in advanced post-training techniques:
First, customized Preference Alignment through Direct Preference Optimization (DPO). During data generation, the system generates five distinct responses using temperature sampling (ensuring variety) and one response at temperature zero, which is highly likely to doom-loop. An automated jury scores these outputs, explicitly marking the doom-loop response as the "rejected" answer. This trains the model exactly what not to do.
Second, Reinforcement Learning (RL) with verifiable rewards. By utilizing verifiable reward structures - such as requiring a definitive mathematical answer or a specific extracted JSON key to grant a positive reward - the model is financially incentivized to reach a conclusion rather than loop endlessly. Combining this with strict n-gram repetition penalties virtually eliminates the doom-loop problem, transforming an unstable edge model into a highly reliable workflow engine.