
Autonomous AI agent workflows are self-improving automation systems where an orchestrator agent continuously generates, tests, and refines business processes — without human intervention. Unlike static automations that execute the same task repeatedly, these pipelines measure objective metrics, accumulate learnings, and iterate around the clock, compounding small efficiency gains into massive operational advantages over time.
Every day, operations and revenue teams lose thousands of hours to manual optimization. At Ability.ai, we see teams launch a campaign, wait for the data, analyze the results, and manually deploy a new iteration. But this human-in-the-loop bottleneck is rapidly becoming obsolete. The operational landscape is shifting toward autonomous AI agent workflows that do not just execute static tasks — they actively and continuously improve them.
By applying advanced machine learning research principles to daily business workflows, operations leaders can build self-improving pipelines. These governed agent systems optimize revenue-generating assets 24 hours a day, requiring zero manual intervention while strictly adhering to corporate guardrails. The shift from fragmented AI experimentation to reliable, self-evolving operational systems represents the next major competitive advantage for the scaling mid-market enterprise.
The evolution from static automation to self-improving AI
Recent developments in machine learning research have revealed a powerful new framework often referred to as "auto research." Pioneered by leading AI researchers, the core concept is elegantly simple — instead of humans training models, we can deploy models to train other models autonomously.
In a laboratory setting, this involves giving an AI agent a small training environment and letting it experiment autonomously overnight. The agent modifies the code, runs a brief training cycle, checks if the validation loss improved, keeps or discards the changes, and repeats the loop. By morning, the researcher wakes up to a detailed log of automated experiments and a measurably smarter model.
For business operations, this exact architectural framework translates directly to revenue and efficiency metrics. Instead of optimizing a machine learning model's validation loss, an orchestrator agent can optimize a company's cold email reply rates, landing page conversions, or advertising costs. The AI formulates a hypothesis, deploys a test, measures the objective business metric, and iterates.
This fundamentally transforms how businesses scale. You are no longer constrained by the working hours of your operations team. An automated pipeline can run parallel AI workflows simultaneously, compounding small efficiency gains into massive operational advantages over time.
Autonomous AI agent workflows: the architecture of continuous optimization
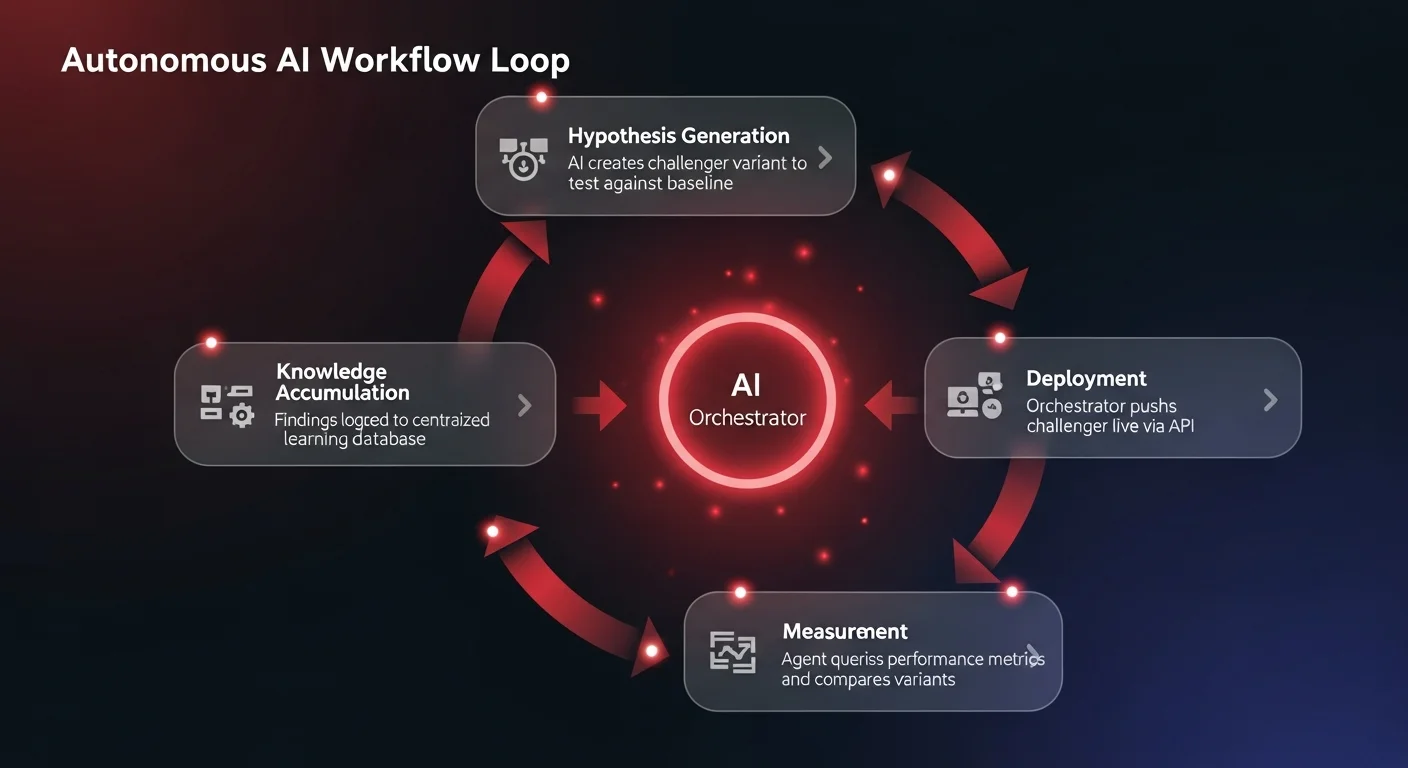
Building a self-improving AI workflow requires a specific structural hierarchy, beginning with an orchestrator agent. Think of the orchestrator as the conductor of a symphony — it manages the high-level logic and delegates specific actions to sub-agents or specialized tools.
To operate autonomously, the orchestrator follows a strict, repeating loop:
- Hypothesis generation: The system generates a "challenger" to compete against the current "baseline." For example, if the baseline is a standard sales email, the challenger might be a variant rewritten to be under 75 words, front-loading the value proposition, and ending with a specific chronological call-to-action.
- Deployment: Using application programming interfaces (APIs), the orchestrator deploys the challenger into a live environment alongside the baseline.
- Measurement: After a predetermined time, the agent queries the platform's API to harvest the results, comparing the performance of both variants against a strictly defined metric.
- Knowledge accumulation: This is the most critical step. The agent logs its findings — both successes and failures — into a centralized knowledge document.
This accumulated intelligence ensures the system never starts from scratch. As the workflow matures, the orchestrator references a constantly growing database of proven, company-specific best practices, allowing future challengers to launch from an increasingly sophisticated baseline. This mirrors the hierarchical AI agent structure that the most effective enterprise deployments use to manage complexity.
Three prerequisites for autonomous experimentation
While the concept of self-improving systems is compelling, not every business process is suitable for autonomous optimization. To successfully deploy this architecture, operations teams must ensure three non-negotiable prerequisites are met.
First, the workflow must have a fast feedback loop. The mathematical advantage of autonomous agents lies in volume. If an experiment takes three months to yield results — such as an enterprise sales cycle — the agent cannot iterate fast enough to provide compounding value. Conversely, workflows with rapid feedback loops allow an agent to run dozens of experiments daily, accelerating the path to optimization.
Second, the system requires an objective, quantifiable metric. Autonomous agents cannot optimize for subjective concepts like "brand warmth" or "customer happiness" unless those concepts are tethered to hard data proxies. Reply rates, click-through rates, and conversion percentages are ideal because they provide an indisputable mathematical signal for the agent to follow.
Third, the orchestrator must have direct API access to manipulate inputs. If an agent formulates a brilliant optimization strategy but requires a human to log into a dashboard and manually change the text, the autonomous loop is broken. The agent must be authorized to pull metrics, generate assets, and push those assets live programmatically.
