Company brain AI automation is the practice of building a centralized intelligence layer that transforms scattered organizational knowledge into executable skills for autonomous AI agents. Without this missing layer, enterprises face a domain knowledge bottleneck - not a model capability gap - that blocks reliable AI automation at scale.
To achieve reliable enterprise AI automation, the primary hurdle organizations face has fundamentally shifted. The biggest blocker to AI automation is no longer the underlying models. Over the past year, foundational AI models have become incredibly capable, fast, and cost-effective. Today, the real bottleneck is the domain knowledge trapped inside your company.
Every business possesses critical operational know-how that is scattered across disjointed systems. Some of it lives entirely in people's heads. The rest is buried in years-old email threads, fragmented Slack channels, unresolved support tickets, or siloed databases. Human-led companies manage to function in this environment only because employees possess a vague, intuitive memory of where that knowledge resides and how to apply it contextually.
But AI agents cannot operate on intuition or vague memory. If we want organizations to truly run on reliable AI automation, we need a new foundational primitive - a company brain.
This system must act as a centralized intelligence layer that pulls knowledge out of fragmented sources, structures it, keeps it current, and translates it into executable skills files for AI agents. Only then can businesses bridge the gap between raw, unstructured company data and safe, consistent AI operations.
The true bottleneck in company brain AI automation
For the past few years, the narrative around artificial intelligence has focused heavily on model capabilities - context windows, reasoning benchmarks, and parameter counts. Operations leaders eagerly awaited the day when models would be "smart enough" to handle their core business workflows.
That day has arrived, yet widespread operational automation remains elusive for many mid-market and scaling companies. The failure point is not the technology itself, but the operational environment into which the technology is deployed.
When a human employee is asked to process a complex pricing exception, they do not simply read a static standard operating procedure (SOP). They might recall a similar situation from six months ago, search their Slack history for the VP of Sales' prior guidance, check a specific CRM field to verify the customer's lifetime value, and finally ping a colleague for confirmation. Humans bridge the gaps in unstructured knowledge through context and experience.
When organizations attempt to automate this same process with AI, they typically point an agent at a handful of static documents and expect it to perform. Without the explicit, mapped context - the tribal knowledge of how the business actually functions - the agent fails, hallucinates, or requires constant human intervention. This is why AI agent context is the real business moat, not the model itself.
Why chatbots and enterprise search fail operations
Recognizing the knowledge gap, many companies have attempted to solve the problem by deploying internal chatbots or AI-powered enterprise search tools. While these tools can summarize documents or help employees find information faster, they fall drastically short of actual automation.
A chatbot over documents is not a company brain. Enterprise search is not a company brain.
These solutions rely on basic Retrieval-Augmented Generation (RAG). They are passive systems designed to present information to a human, who must then interpret the data, make a decision, and physically execute the work across various software platforms.
Furthermore, the proliferation of random, ungoverned AI chatbots across departments inevitably leads to Shadow AI sprawl. Employees begin using disconnected tools, sharing sensitive data outside of secure boundaries, and creating fragmented workflows that IT and Operations leaders cannot observe, govern, or control. This pattern of ungoverned AI agents creates compounding technical debt that becomes progressively harder to unwind.
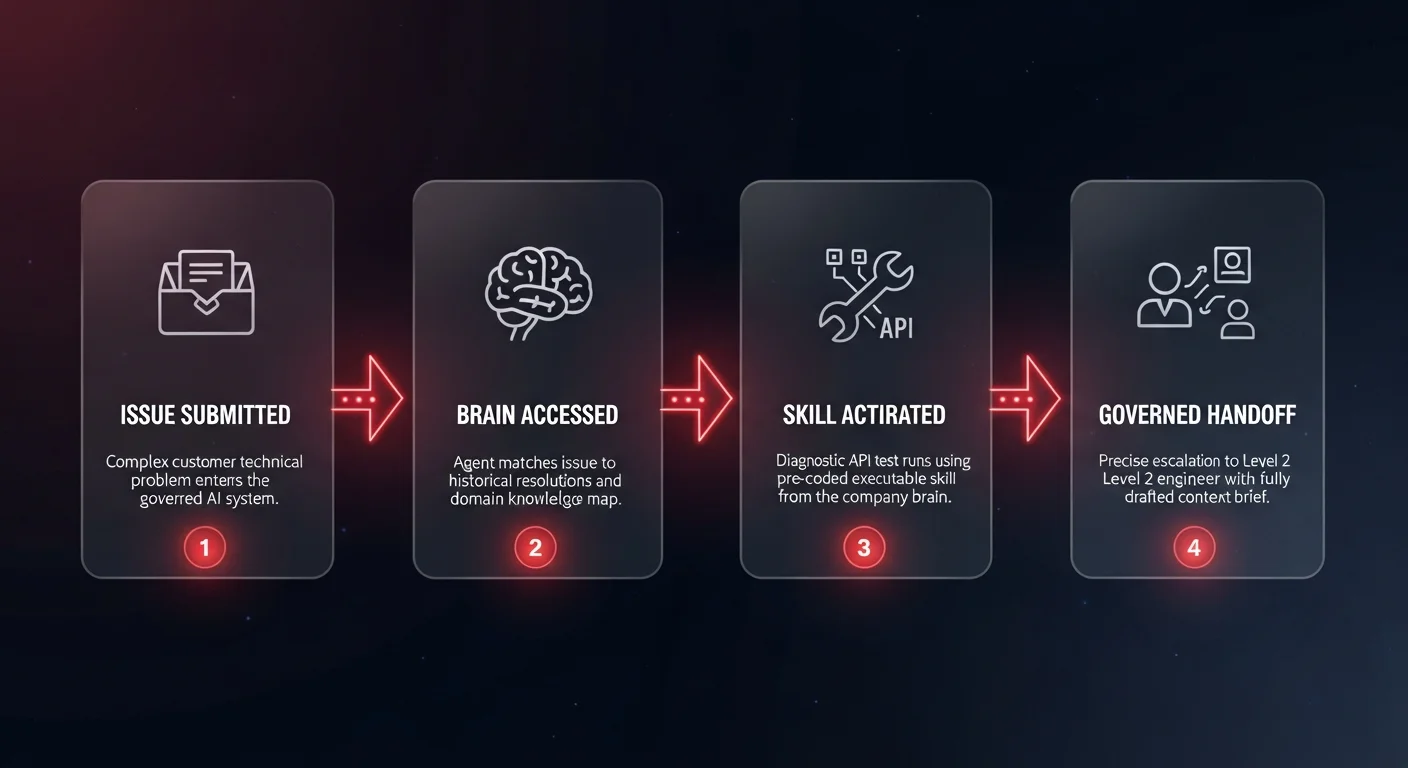
To move from passive information retrieval to active, autonomous execution, organizations need a living map of how the company works. This map must detail exactly how refunds get handled, how pricing exceptions are decided, and how engineers must respond to technical incidents.
Anatomy of a company brain: structuring the unstructured
A true company brain serves as the missing layer between raw organizational data and reliable AI automation. It is an active, governed architecture designed specifically to support autonomous agents. Building this layer requires three distinct operational phases.
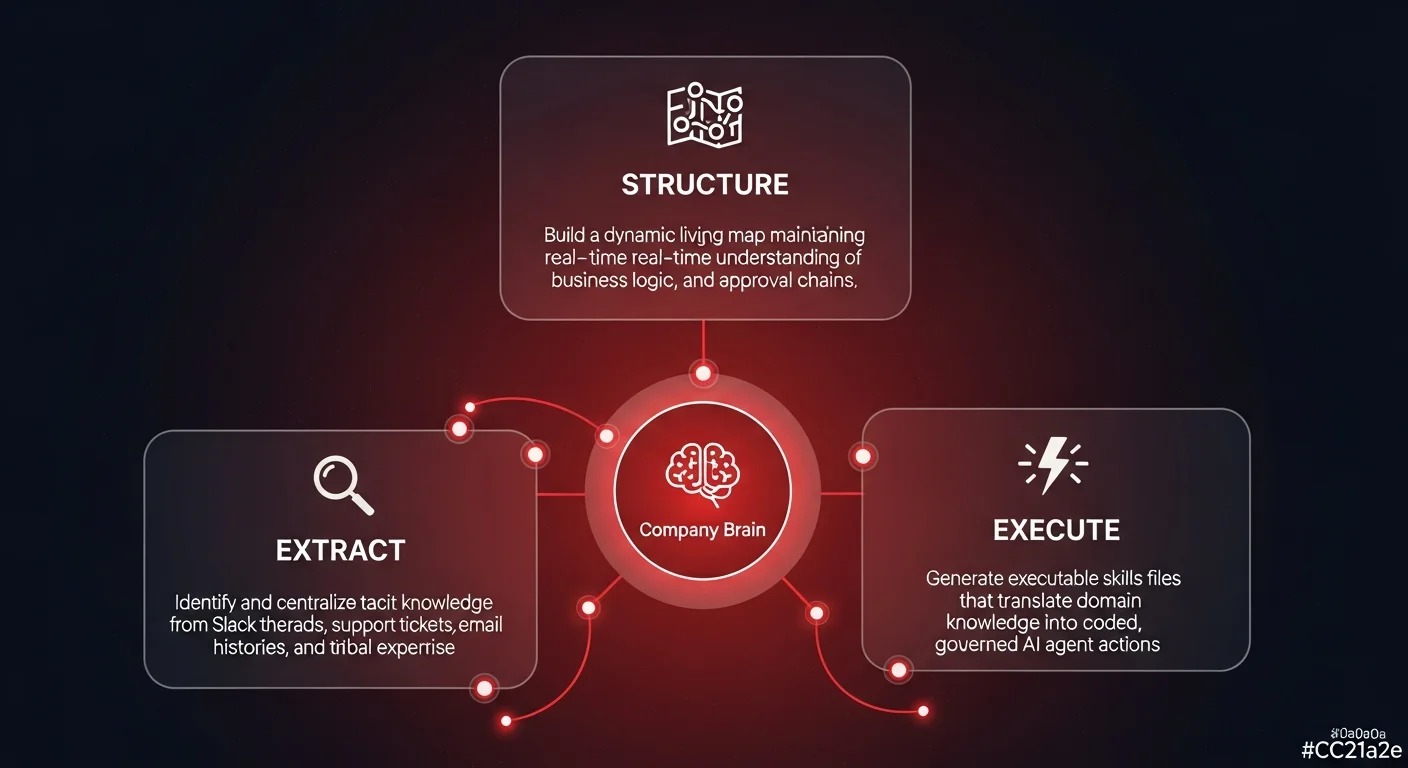
Extracting and centralizing domain knowledge
The first step is identifying and extracting the tacit knowledge required to execute specific workflows. This means analyzing not just official documentation, but the digital exhaust of the company - support tickets that show how edge cases were resolved, Slack threads detailing approval chains, and email histories that reveal client management nuances.
Structuring the living map
Once extracted, this knowledge must be structured into a dynamic, living map. Unlike static wikis that become outdated the moment they are published, a company brain must maintain a real-time understanding of business logic. If the threshold for a manager's approval on a refund changes from fifty dollars to one hundred dollars, the map must reflect this globally, instantly updating the operational boundaries for all AI agents.
Generating executable skills files
This is the most critical component. Structured knowledge must be translated into what are essentially executable skills files. An AI agent doesn't just need to know the refund policy; it needs the explicit, coded skill to log into the payment system, verify the transaction, calculate the prorated amount, execute the API call to issue the refund, and update the CRM - all while adhering to the company's mapped business logic.