AI context infrastructure is the governed layer of data, permissions, and automation that enables AI agents to act on accurate, role-appropriate business information - replacing manual prompting with a centralized business operating system. Organizations that build this infrastructure move from fragmented, isolated AI interactions to autonomous agents that drive measurable operational outcomes.
Generative AI agents are evolving rapidly, capable of executing complex workflows, writing code, and running entire business processes autonomously. But regardless of the underlying model, an agent is only as capable as the information it can access. For mid-market operations leaders, building a robust AI context infrastructure is the defining challenge of the year. The businesses that will extract the most operational value from AI are not the ones with the best prompts, but the ones with the most governed, persistent, and automated context layers.
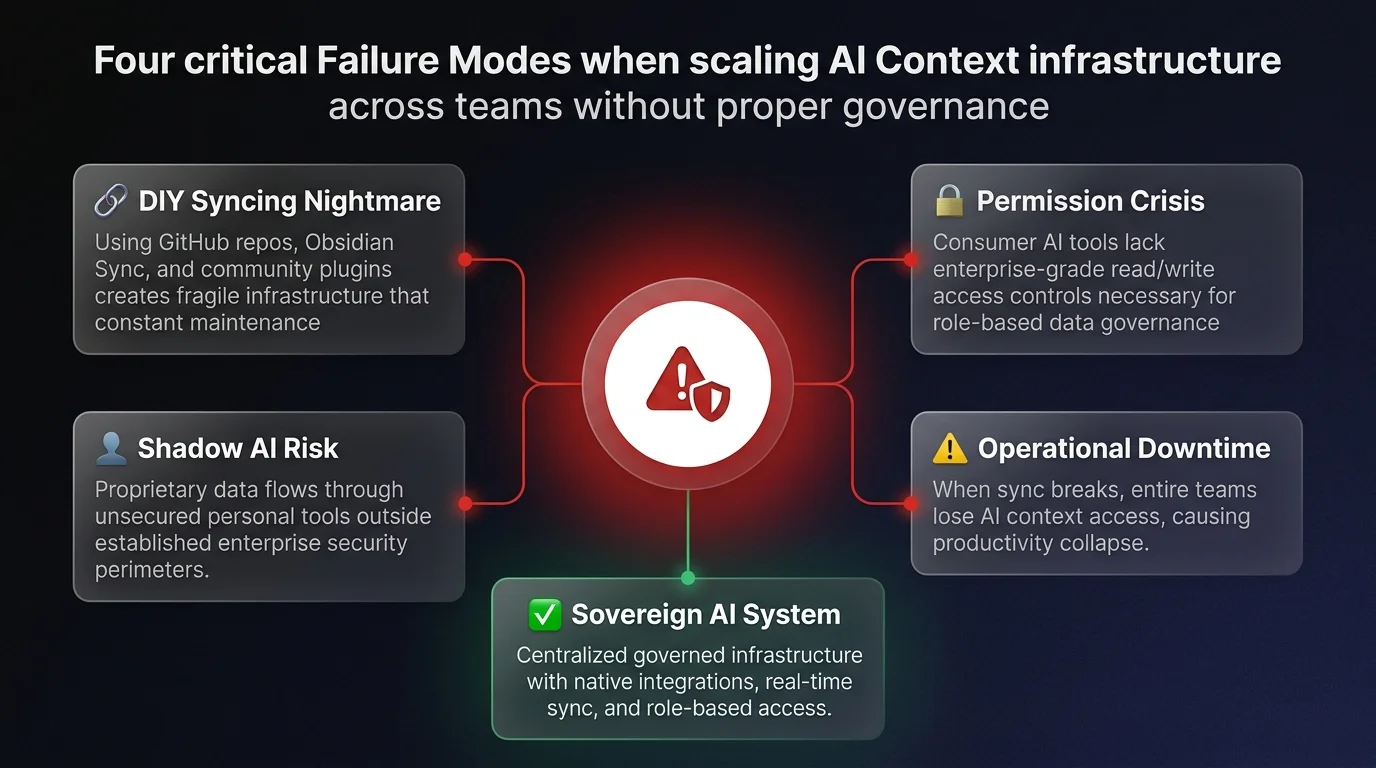
Recent industry research and deployment analyses reveal a clear maturity curve in how businesses deploy AI - transitioning from fragmented manual inputs to a fully integrated business operating system. However, this journey exposes critical vulnerabilities in data governance and team-wide permissions.
Here is a deep dive into the seven levels of AI context maturity, the operational risks hidden within DIY solutions, and how operations leaders can build secure, agentic workflows.
The trap of manual context and isolated AI projects
The vast majority of business users are currently stuck at the baseline level of AI maturity: manually providing context to a language model in every single chat, or worse, providing no context at all.
If an employee asks an AI to write a LinkedIn post or draft a client email without organizational context, the result is heavily generalized text that screams AI. To get a high-quality output, the user must manually input context around the business's ideal customer profile (ICP), the brand's tone of voice, examples of previous successful work, and strict guardrails. While this improves the output, manually copy-pasting this data is an incredible drain on productivity.
To solve this, users naturally graduate to using chat-based projects. In this setup, users upload core context files and system instructions into a dedicated workspace. This eliminates the need to rewrite instructions for repetitive tasks. However, this approach creates immediate operational bottlenecks:
- Isolated silos: Projects live in separated chat windows. A team member must constantly hop between a "content creation" project and a "data analysis" project.
- Static information: The AI cannot autonomously update its own context files. If the company ICP changes, a human must manually upload the new document to every single isolated project.
- Lack of cross-pollination: Operations are rarely isolated to a single task. A strategy insight discovered in a planning chat cannot easily be transferred to an execution project.
Activating AI context infrastructure with skills and dynamic file access
To break out of isolated chat windows, organizations must transition toward AI skills and dynamic file access. This represents a fundamental shift from treating AI as a static tool to deploying it as a dynamic workflow participant.
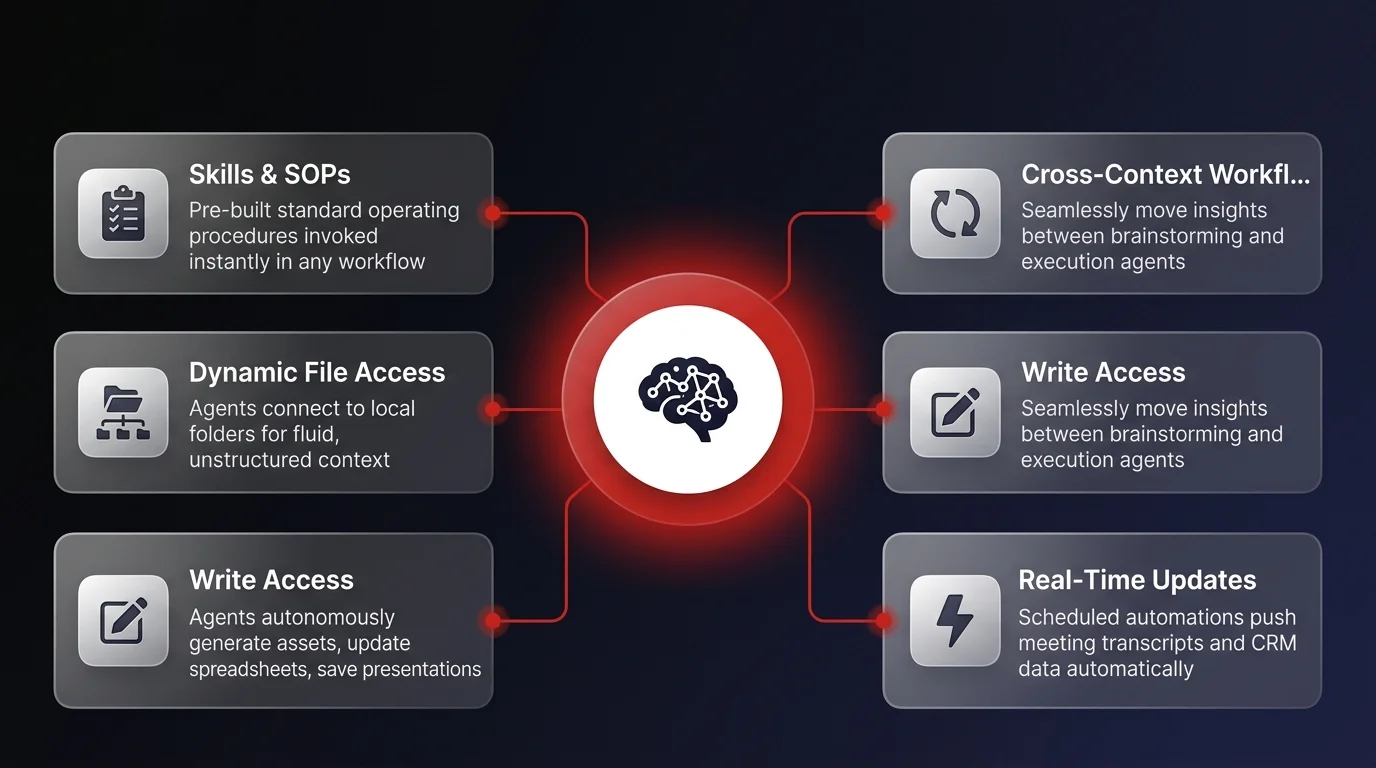
Deploying pre-established SOPs via skills
Unlike isolated projects, AI skills can be invoked in any chat at any moment. A skill essentially bundles a system prompt (the standard operating procedure) with a specific set of reference files.
For example, an operations manager might be in a brainstorming chat with an AI agent. Mid-conversation, they can trigger a pre-built "Process Documentation" skill. The agent instantly pulls the company's formatting guidelines, references the brainstorming session, and autonomously drafts the formal documentation. Furthermore, these skills can be tested using built-in evaluation frameworks to ensure the output consistently meets business standards regarding sentence structure, word count, and tone.
The power of local file access
While skills handle pre-established workflows, much of daily business operations - like strategic planning and ad-hoc problem solving - require fluid, unstructured context. This is where giving AI agents dynamic access to local file systems transforms the operational landscape.
By connecting an agent to a specific local folder, the AI gains instant context on business strategy, historical meeting transcripts, and current objectives. More importantly, it gains write access. The agent is no longer just reading documents; it can autonomously generate new assets, update spreadsheets, and save presentations directly into the designated business folder.
As we covered in our deep dive on autonomous AI agent governance, this write-access capability is also where governance requirements emerge - the moment agents can modify business data, organizations need observable logic and access controls.
Centralizing knowledge into an AI operating system
As agents generate and update more files, the context data grows exponentially. Managing this growing ecosystem introduces a new operational challenge: fragmentation.
If a business maintains shared context files across dozens of different projects and agent skills, updating a core document - like a primary sales script - requires manual updates across the entire network. The solution is consolidating all organizational context into a centralized "Second Brain" or personal operating system.
Automated context roll-ups
In a centralized OS model, all context files are routed into a single, highly structured directory. The true power of this level unlocks when businesses introduce scheduled tasks to keep this knowledge base updated in real time.
For example, an organization can configure a scheduled automation via tools like Fireflies to push all daily meeting transcripts directly into the central context folder. Another automated task can pull daily CRM analytics or team productivity metrics and deposit them into the agent's brain. When an executive logs in for a morning briefing, the AI agent pulls from this live, automatically updated dataset to provide an accurate overview of business priorities for the day.
The necessity of an instruction layer
As the knowledge base scales, the AI needs a governance layer to understand how to navigate the data. Industry power users accomplish this by utilizing a core instruction file - often labeled as a claude.md or an index file.
This file acts as a traffic director. It provides the agent with strict routing rules: where to pull specific information, how the folders are structured, and what guardrails to follow when updating files. For massive datasets, individual subfolders require their own index files so the agent does not get lost in the noise.