AI agent context is the persistent, sovereign memory layer that transforms isolated AI chats into governed autonomous workflows. Organizations that implement centralized context architecture compound their institutional intelligence with every interaction - creating a business moat that off-the-shelf models cannot replicate.
Every month, enterprise AI tools become more capable at reasoning, writing code, and navigating software. Yet, as operations leaders attempt to deploy these tools across their organizations, a glaring operational bottleneck remains. Mastering AI agent context is the critical missing layer between basic productivity experiments and truly autonomous, governed workflows.
Currently, most organizations suffer from what we call "AI sprawl." Teams are using powerful models, but they are doing so in isolated silos. For AI agents to actually become the main interface for enterprise work, they require a persistent, sovereign memory architecture.
Our research into advanced agent deployments reveals that building a centralized knowledge operating system - often referred to as a "second brain" - fundamentally changes how businesses scale AI. By providing agents with persistent memory around business strategy, workflows, and operational rules, companies can transform fragmented AI usage into reliable, governed operational systems.
The crisis of isolated AI conversations
Right now, most professionals use AI in isolated, ephemeral conversations. In every new chat session, users must re-explain their entire business situation. They have to continually feed the AI information about their ideal customer profile (ICP), their brand guidelines, their active projects, and their specific operational workflows.
This creates massive operational friction. The intelligence of the AI is bottlenecked by the user's willingness to write exhaustive prompts repeatedly. Furthermore, this isolated approach creates severe governance issues. If every employee is feeding slightly different context into their individual AI chats, the organization suffers from inconsistent outputs, fragmented logic, and a total lack of strategic alignment.
To move beyond this, AI agents need persistent access to detailed context - not just a few static facts, but dynamic, interrelated knowledge covering business strategy, team dynamics, meeting histories, and active priorities.
For a deeper look at why context outperforms prompt engineering alone, read why context beats prompt engineering.
How AI agent context creates a sovereign knowledge architecture
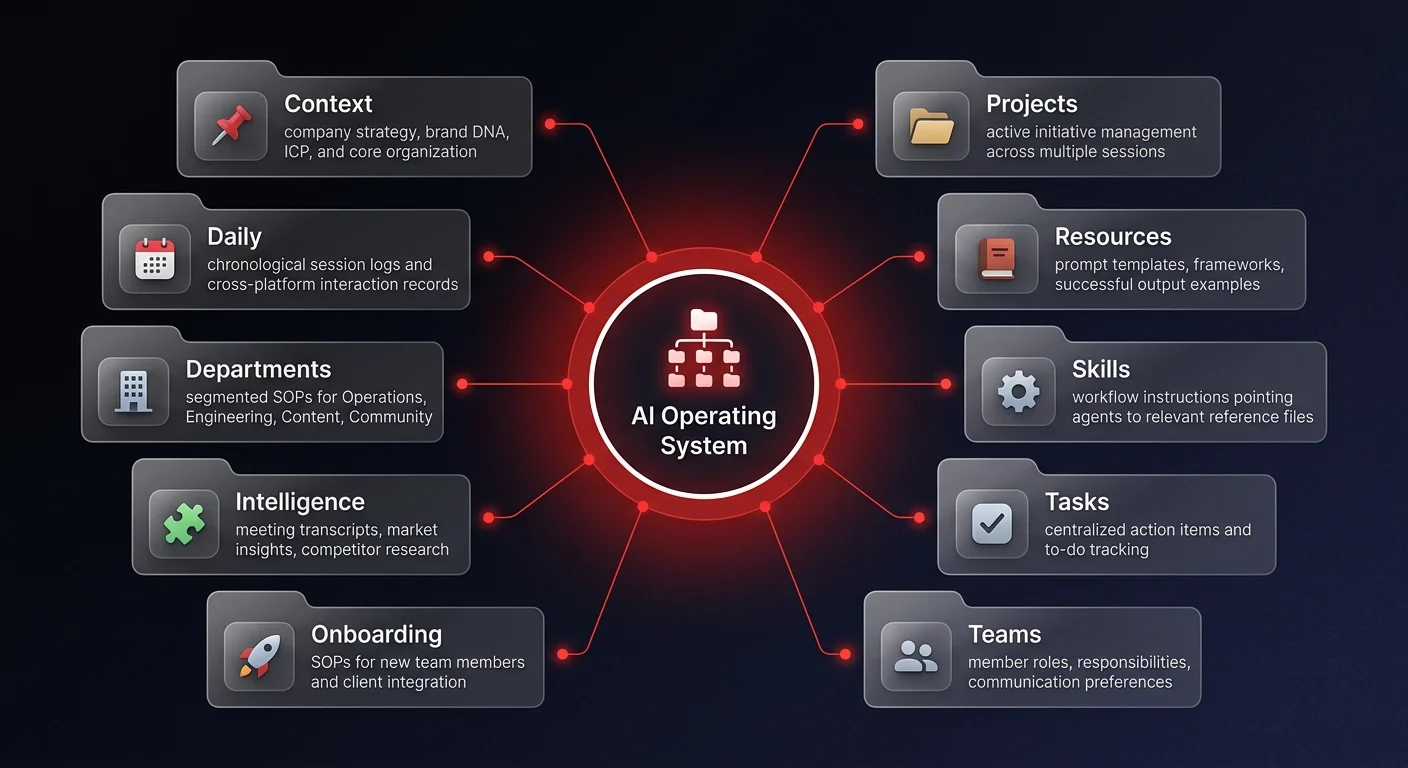
Industry implementations reveal a highly effective solution: structuring business knowledge in a centralized, local directory of markdown files. Applications like Obsidian are frequently used to provide a visual overlay for these local folders, allowing users to navigate, search, and link documents together.
By pointing AI agents - whether that is Claude Code, Codex, or customized enterprise bots - directly to this local folder, you grant them continuous read and write access to your company's operational reality. Because this folder lives locally or within a controlled virtual private cloud (VPC), it ensures strict data sovereignty. You are not relying on a third-party SaaS application's opaque memory features; you own the context.
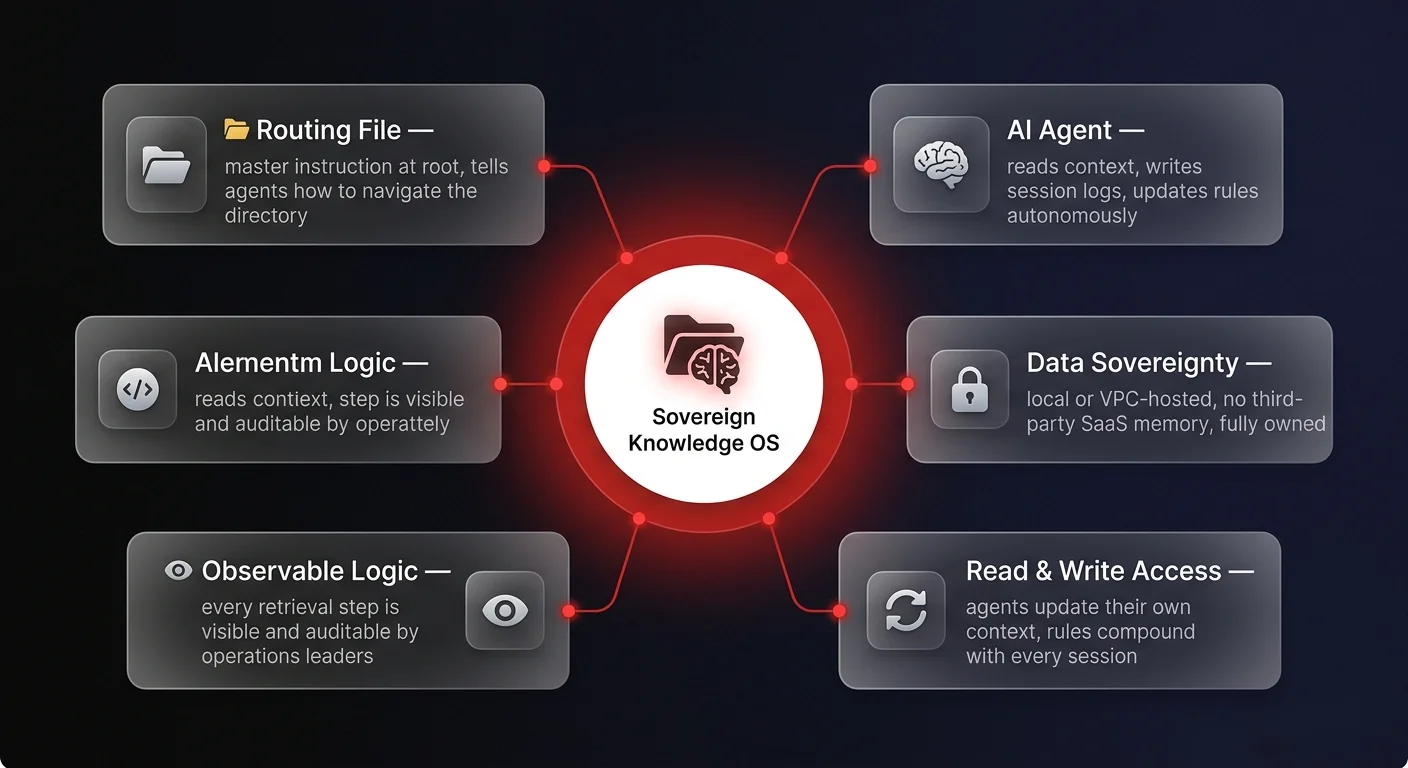
The critical component of this architecture is the routing layer. In many successful deployments, this takes the form of a master instruction file located at the root of the directory. This file acts as a system prompt. It provides the AI agent with explicit instructions on how to navigate the folder structure, where to retrieve specific types of information, and where to save new data.
When a user asks, "What did we talk about in our team meeting yesterday?" the agent first reads the routing file to understand the architecture, navigates to the specific folder containing yesterday's meeting transcripts, reads the context, and formulates an accurate answer. This creates entirely observable logic - operations leaders can see exactly how the AI retrieves and processes information.
For a practical guide to structuring this context, see how to structure context for AI agents.
Five operational advantages of centralized AI memory
Deploying a governed context architecture yields five compounding advantages for scaling organizations.
1. Persistent, cross-platform context
With a centralized knowledge base, an AI agent instantly understands the user's priorities without a lengthy preamble. When an executive opens a new session and asks, "What should I focus on today?" the agent can instantly pull context from the operating system. It cross-references current company goals, recent meeting notes, and project files to output a highly specific directive - for example, prioritizing landing page copy changes, recording specific video assets, and organizing an upcoming corporate offsite.
2. Autonomous system updates
Unlike static databases, a properly governed AI agent can directly update its own context. Any decision, rule, or project update made during an AI workflow can be logged directly back into the system.
For instance, if an executive reviews an AI-generated piece of content and provides feedback such as, "never use em dashes when writing content for me," they can instruct the agent to save this rule. The agent will autonomously navigate to the "writing preferences" document within the system and log the new rule. From that moment on, every piece of content generated by the system will adhere to this guideline. This means the system becomes inherently smarter and more tailored with every interaction.
3. Streamlined skill and workflow architecture
In standard AI deployments, automated workflows (often called "skills") require massive amounts of embedded context. A workflow designed to write a LinkedIn post typically requires the creator to manually embed the company's ICP document, brand voice guidelines, and formatting templates directly into the prompt.
With a centralized AI agent context architecture, this paradigm shifts. Operations teams no longer need to embed reference files into individual skills. Instead, the workflow instructions simply point the agent toward the relevant files in the central directory.
This is a massive governance victory. If the marketing team updates the central ICP document to target a new demographic, every single automated skill that references the ICP - from newsletter generation to outbound sales emails - is instantly and automatically updated. It eliminates the maintenance nightmare of updating dozens of disconnected prompts.
4. Agnostic infrastructure for any LLM
Because the second brain is simply a structured directory of markdown files, it is completely model-agnostic. Organizations can point Claude, Codex, or specialized enterprise models at the exact same folder. This prevents vendor lock-in and allows operations leaders to route specific tasks to whichever model is currently best suited for the job, all while utilizing the exact same underlying business context.
5. Scalable team intelligence
The true power of this system emerges when it is scaled across an entire business. By syncing this context directory across a team, every employee's AI agent operates from the same single source of truth.
An engineer can ask their agent to draft a client communication, and the agent will automatically utilize the company's up-to-date tone of voice and strategy documents. This ensures total operational consistency and breaks down the traditional silos between departments.