
System 2 AI is an architectural approach that separates deterministic calculation from language generation to eliminate AI hallucinations in business operations. By routing strict business logic through rule-based engines before passing structured data to LLMs for natural language output, organizations stop the root cause of AI failures - asking language models to perform calculations they were never designed to handle.
Organizations are rapidly discovering that large language models are exactly that - language models. They are exceptional at parsing context and generating text, but they are fundamentally flawed when asked to perform strict calculations or apply rigid business rules. When employees rely on ungoverned tools like ChatGPT to execute complex operational logic, the result is shadow AI sprawl and costly hallucinations. To solve this, operations leaders must adopt System 2 AI - an architectural approach that pairs autonomous reasoning with deterministic tools.
Recent engineering insights from Take Take Take - a chess platform founded by world champion Magnus Carlsen - provide a masterclass in this exact architecture. By examining how their engineering team built an AI-powered chess coach that successfully avoids hallucinations, business leaders can extract a perfect blueprint for deploying reliable, governed AI systems in enterprise operations.
Why large language models fail at business calculations
The intersection of chess and artificial intelligence has a long history, dating back to Claude Shannon's 1949 paper on programming computers to play chess. While traditional brute-force engines and intuitive neural networks (like DeepMind's AlphaZero) eventually surpassed grandmaster levels, modern LLMs struggle to play the game reliably.
During a recent AI tournament hosted by Kaggle, Magnus Carlsen observed an LLM playing the "poison pawn line" in a chess opening. The model completely hallucinated its position, not because it misunderstood the opening theory, but because transformer architectures cannot inherently calculate strict positional logic step-by-step. High-reasoning models can simulate calculation through reasoning tokens, but they quickly fall apart when the logic tree becomes too complex.
The business parallel here is critical. If an LLM cannot track pieces on an 8x8 board without hallucinating, it certainly cannot calculate tiered commission payouts, determine optimal supply chain routing, or enforce strict legal compliance across a 50-page vendor contract. Asking a standalone LLM to perform rigid business operations is the root cause of corporate AI failures.
System 2 AI architecture: separating logic from language
To build a reliable AI coach, the engineering team had to bridge the gap between traditional chess computers (which play flawlessly but cannot speak) and LLMs (which speak fluently but cannot calculate). Their solution was a strict decoupling of business logic from language generation.
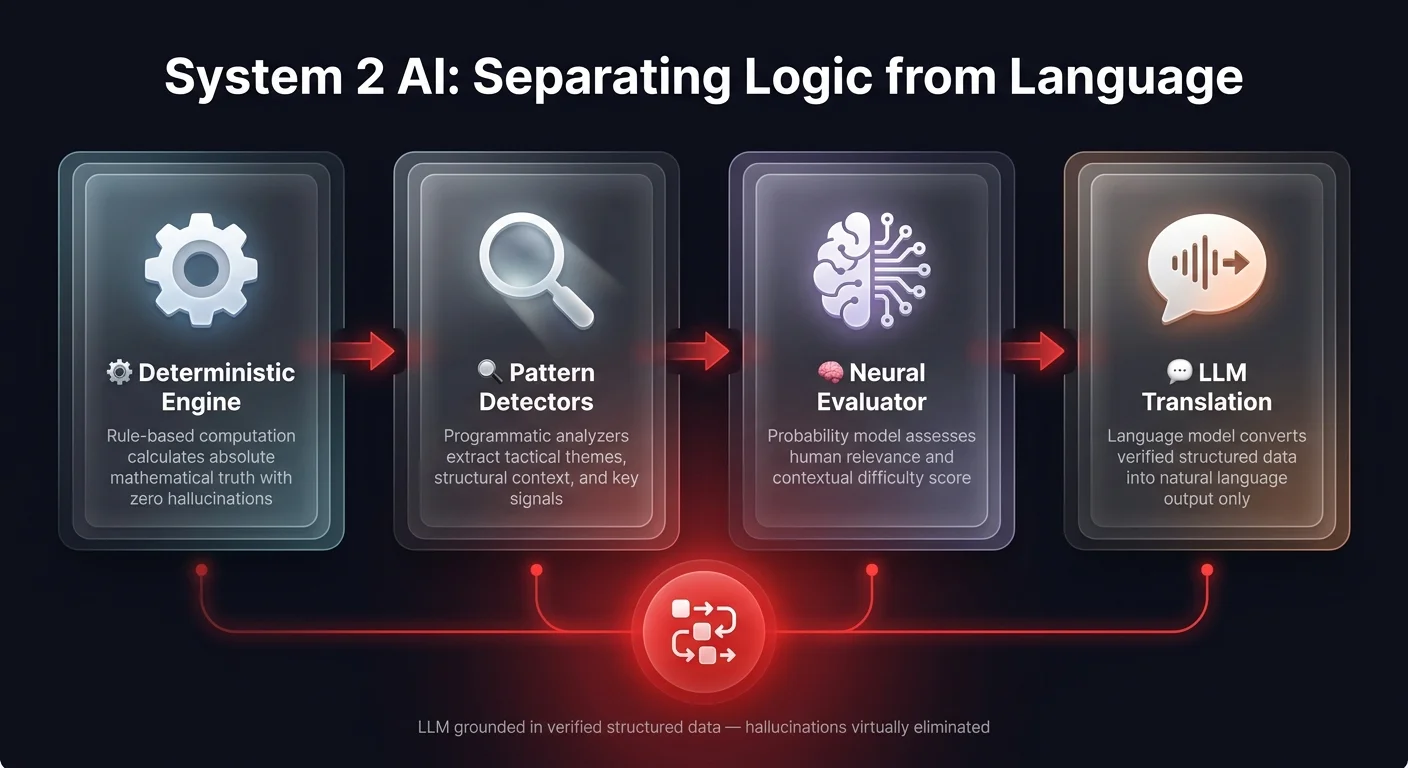
When a game concludes, the pipeline does not ask the LLM to analyze the moves. Instead, a deterministic, traditional chess engine called Stockfish analyzes the board to find the absolute truth - the mathematical best move. Next, the system runs a series of programmatic detectors to extract structural context, identifying tactical themes like forks, pins, and positional disadvantages. Finally, a neural network called Maya evaluates the probability of a human finding that specific move based on their rating.
Only after this robust, deterministic data pipeline is complete does the LLM enter the workflow. The LLM's job is restricted entirely to translating this rich, structured JSON data into natural English commentary. Because the model is strictly grounded in the provided context, hallucinations are virtually eliminated.
For operations leaders, this is the definition of System 2 AI. When deploying sovereign AI agent systems for specific business outcomes, you must separate the workflow. Deterministic workflow automation tools should query the CRM, run the calculations, and enforce the business rules. The LLM should only be used as the translation and reasoning layer on top of that ground truth.
Autonomous triage loops and human oversight
One of the most impressive operational components of this chess architecture is the closed-loop autonomous triage system used for quality assurance. In any consumer application or enterprise software, handling edge cases and user feedback is a massive operational bottleneck.
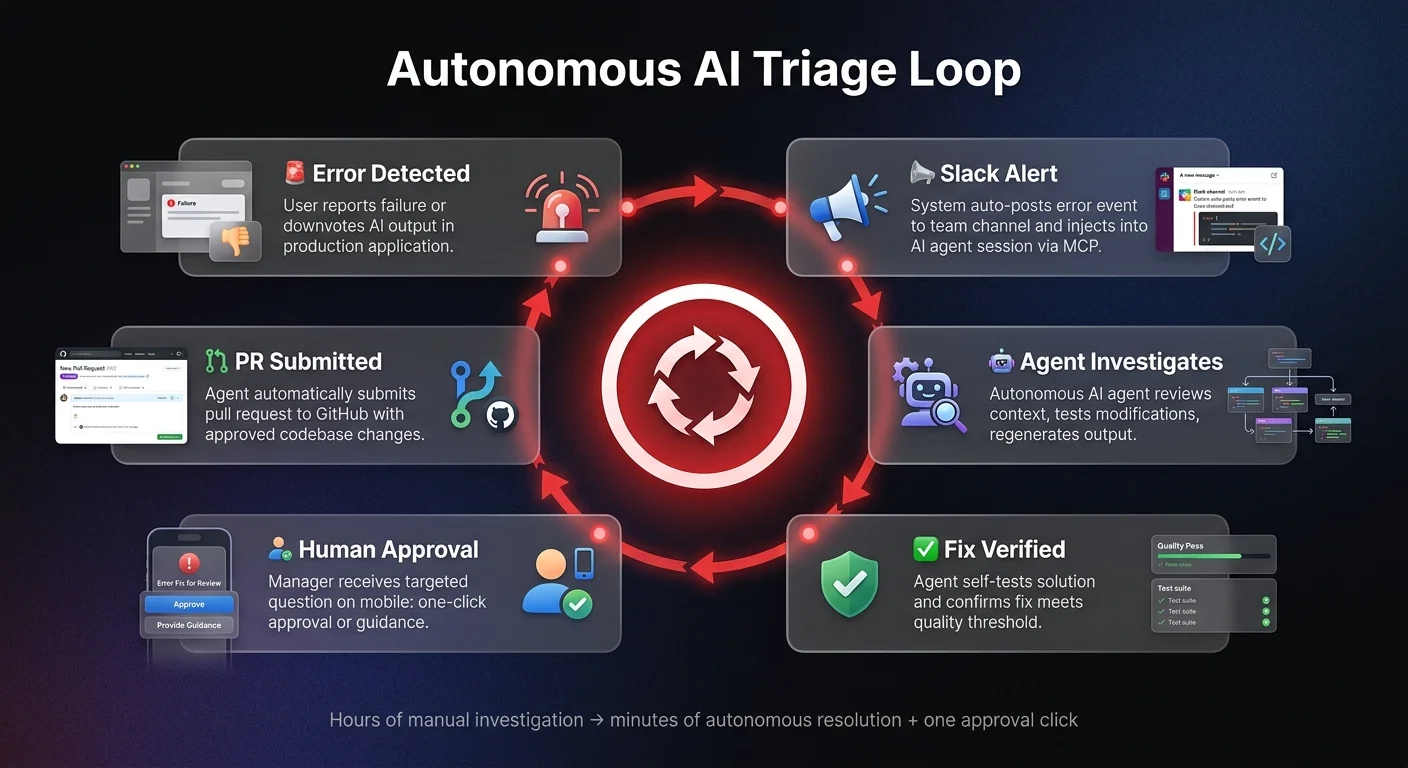
When a user downvotes an AI-generated comment in the application, the system automatically posts the event to a Slack channel and simultaneously injects the event into a Claude Code session via an MCP (Model Context Protocol) server. The autonomous agent immediately begins investigating the failure. It invokes a triage skill, reviews the context, tests prompt modifications, and regenerates the commentary.
Once the agent verifies its own fix, it pings the engineering team directly in Slack, asking a specific question like: "What specifically feels wrong about the commentary?" or offering a solution. A human reviewer can guide the agent from their mobile phone while riding the bus. Once approved, the agent automatically submits a pull request to GitHub to update the codebase.
This autonomous triage loop represents a massive opportunity for RevOps and Customer Support teams. Instead of human agents manually investigating every support ticket or CRM data error, organizations can deploy a focused AI implementation that routes error reports directly to an autonomous agent. The agent does the heavy lifting of investigating the database, drafting the fix, and simply requesting an approval click from a human manager. See how automated task management and workflow automation can streamline this exact pattern in your operations.