GPT-5.4 operational risks are the governance and data integrity challenges that emerge when deploying frontier AI models—like OpenAI's latest release—in enterprise environments where the model beats human baselines 70% of the time yet fabricates answers 89% of the time it is uncertain. For COOs and scaling companies, this combination of impressive capability and dangerous failure modes demands governed agent infrastructure rather than raw model access.
For mid-market and scaling companies, ignoring these frontier AI developments is more costly than ever. Yet, navigating the current landscape is exceptionally murky. The industry is currently flooded with self-reported benchmarks, leaked memos regarding military contracts, and wildly uneven capability leaps. For operations leaders, CEOs, and COOs, the goal is not to chase the hype, but to understand exactly how these models function under the hood — and more importantly, how they fail.
The central takeaway from recent testing is clear: while new models exhibit breathtaking capabilities in closed-loop software generation, their failure modes are becoming more dangerous for enterprise data. Transforming these raw, fragmented AI experiments into reliable, governed operational systems requires a deep understanding of what GPT-5.4 actually represents.
The illusion of autonomous white-collar work
GPT-5.4 is effectively an attempt to create an autonomous agent for all white-collar professionals. To prove this, the model was blind-graded by experts against human outputs across 44 white-collar occupations — specifically selected for their impact on the global economy in a benchmark known as GDP-VAL.
The headline statistic is striking: GPT-5.4 beats the human first attempt 70.8% of the time. If you include ties, that number jumps to 83%.
Furthermore, the model is demonstrating an almost closed loop of autonomous execution. Across a multitude of benchmarks, GPT-5.4 shows profound progress in computer use. It can write code, execute that code, and then visually review the output to test for accuracy. In practical testing, the model can generate complex, animated league tables for football clubs — performing the necessary web searches, writing the code, and rendering the UI in one shot. It can map historical Viking incursions, recognize when a graphical element like a specific island or city is misplaced, and run in the background to self-correct the visual output.
However, these capabilities create a massive shadow AI risk for operations teams. When employees hear that an AI beats human baselines 70% of the time, they inevitably begin routing sensitive, mission-critical workflows through unverified, raw models. But the GDP-VAL tasks are self-contained and purely digital. They do not represent the messy, multi-dimensional reality of enterprise operations.
If we make an analogy to self-driving cars, the technology might be better than a human mile for mile, but a catastrophic failure in an autonomous vehicle is still unacceptable. In enterprise operations, a single catastrophic hallucination in a financial spreadsheet or a customer data migration can cost millions.
The 89 percent fabrication problem: a data sovereignty crisis
If the GDP-VAL benchmark sounds intimidating enough to replace your operations team, a deeper look at the model's failure modes tells a completely different story.

According to artificial analysis testing on questions that probe for hallucinations, GPT-5.4 performs close to state-of-the-art in overall accuracy. But a critical metric reveals a terrifying reality for business operations: when GPT-5.4 gets things wrong, it fabricates an answer 89% of the time.
Instead of admitting it does not know the answer, the model will confidently output a falsehood. This represents a higher rate of confident hallucination — or fabrication — than several previous iterations. Furthermore, testing shows that GPT-5.4 is slightly more prone to destructive actions — such as deleting hard drives or overwriting code in other tabs — than its predecessor, GPT-5.3 Codex.
This 89% fabrication rate is the ultimate argument against deploying ungoverned raw models in a corporate environment. Enterprises cannot rely on naked LLMs for operations, finance, or customer support. Without a sovereign AI agent system that utilizes observable logic and verification layers, this fabrication rate will cause silent, catastrophic data errors. A high-performing AI that lies confidently is infinitely more dangerous to a scaling company than an average employee who asks for help when confused.
Uneven progress and the myth of generalization
The AI industry is currently divided by a central debate: will models naturally generalize across all specialisms as they scale, or do they require highly specialized, rarefied data for every distinct domain? The performance of GPT-5.4 proves that progress is currently jagged and highly uneven.
While GPT-5.4 shows incredible leaps in general computer use, it regresses in specific, highly technical domains. When tested on OpenAI-Proof Q&A — a rigorous internal benchmark made of 20 actual research and engineering bottlenecks that caused major project delays — the results were counterintuitive. GPT-5.4 actually underperformed GPT-5.3 Codex, GPT-5.2 Codex, and even GPT-5.2.
For operations leaders, this uneven progress destroys the strategy of simply waiting for the next foundational model to solve your business problems. Upgrading from a 5.2 to a 5.4 model might improve email drafting but completely break a specialized data-parsing workflow. Record-breaking performance in one domain does not guarantee competence in another.
This is why relying on a single model's general capabilities is a failing strategy. Businesses require a stable orchestration layer where specific business outcomes are managed by governed agents, rather than constantly migrating workflows to the newest, shiniest model that might silently fail at niche tasks. For a deeper look at agentic AI risks and governance challenges, the structural issues go well beyond any single model release.
Vendor volatility and the rise of safety theater
The operational risks of frontier models extend far beyond technical benchmarks; they are deeply rooted in vendor lock-in and shifting corporate governance. Recent geopolitical and corporate developments highlight exactly why mid-market companies must maintain model-agnostic infrastructure.
The industry recently witnessed a massive fallout regarding military contracts involving the Department of War, Anthropic, and OpenAI. Anthropic, initially positioned as a safety-first organization with strict red lines against autonomous military use, walked away from a massive contract over concerns regarding domestic surveillance and autonomous warfare. OpenAI subsequently stepped in, reportedly utilizing a third-party classification system from Palantir as a safety layer to secure the contract.
Leaked communications from Anthropic leadership described these third-party wrappers as safety theater — a pantomime designed to placate disgruntled employees while effectively allowing the models to be used without meaningful legal restrictions.
Regardless of which corporate narrative you believe, the strategic takeaway for corporate leaders is identical: AI providers will rewrite their terms of service, shift their ethical guardrails, and alter their model behaviors overnight to secure multi-million dollar contracts. We have watched organizations pivot from claiming they only scale models to study safety, to scaling because of peer pressure, to engaging in massive defense contracts.
If your company's operational backbone is hardcoded to a single vendor's API — whether that is OpenAI, Anthropic's Claude, or Google's Gemini — your business continuity is at the mercy of their shifting corporate policies. Understanding AI governance as a CEO responsibility has never been more urgent.
Managing GPT-5.4 operational risks: governed agent systems as the answer
The release of GPT-5.4 confirms that the capabilities of artificial intelligence are accelerating at a staggering pace. We are seeing closed-loop execution where models can generate, test, and visually verify their own outputs. But alongside these miracles comes a reality check: a model that lies 89% of the time it is confused, regresses on specialized tasks, and is governed by highly volatile corporate entities.
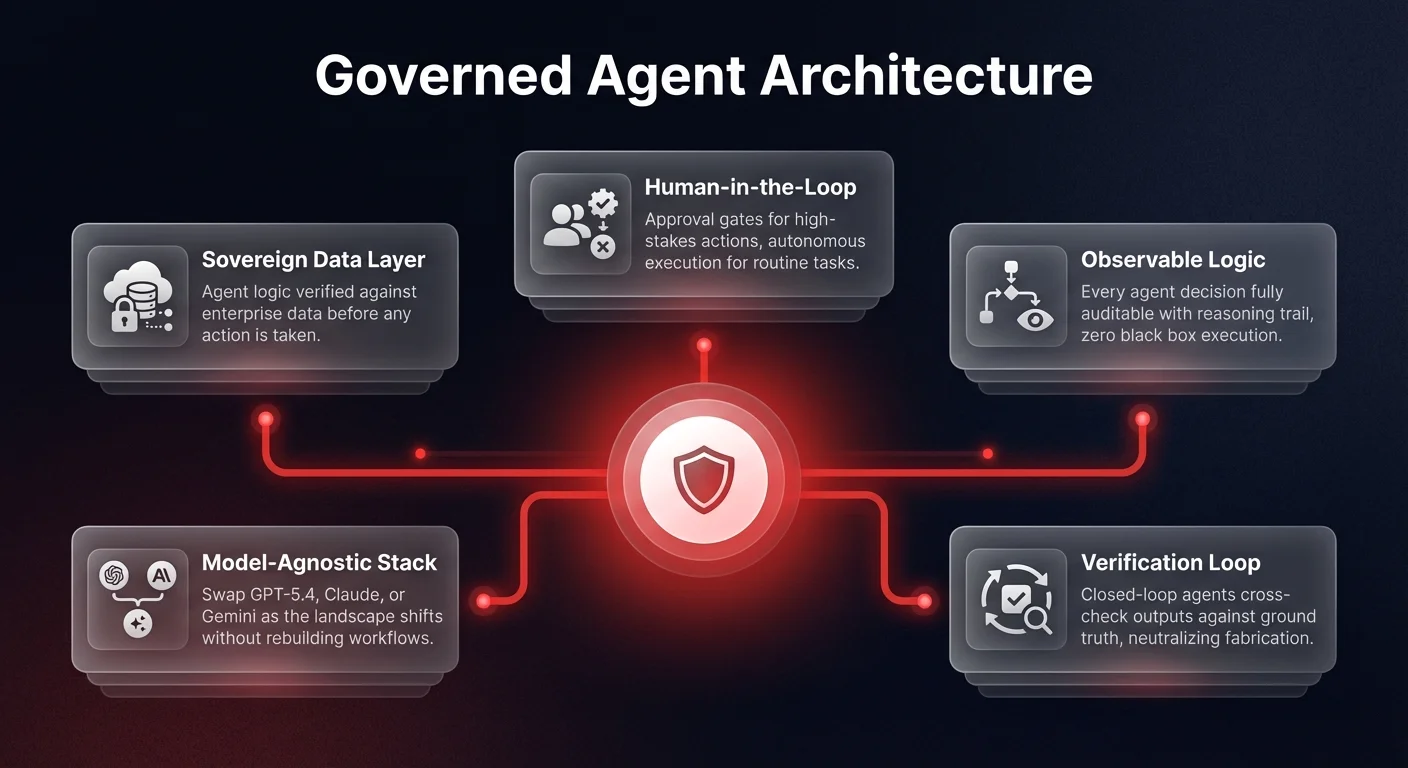
Not using the best AI tools in 2026 is a massive operational risk, but deploying them without governance is corporate malpractice.
The solution is not to ban these tools, but to architect a governed layer between the frontier models and your enterprise data. This is where the concept of sovereign AI agents becomes critical. By deploying agent systems designed for specific business outcomes — rather than relying on generalized chat interfaces — companies can build self-healing workflows. See how Ability.ai's executive AI automation solutions help COOs deploy governed agent infrastructure that neutralizes fabrication risks with built-in verification layers.
An effective orchestration layer takes the incredible closed-loop capabilities of a model like GPT-5.4 and anchors them in observability. When an agent processes a customer support ticket or audits a financial record, it must verify its own logic against your sovereign data, fundamentally neutralizing the 89% fabrication rate.
As the lines between human professions blur and AI models become increasingly autonomous, your competitive advantage will not come from which underlying model you use. It will come from how effectively you govern, orchestrate, and observe the agents executing your business logic. A critical part of that strategy is also understanding the broader SaaS apocalypse driven by AI agents and positioning your operations ahead of the disruption. Explore Ability.ai's finance and procurement automation to see how governed agent systems protect financial data from fabrication errors in production environments.